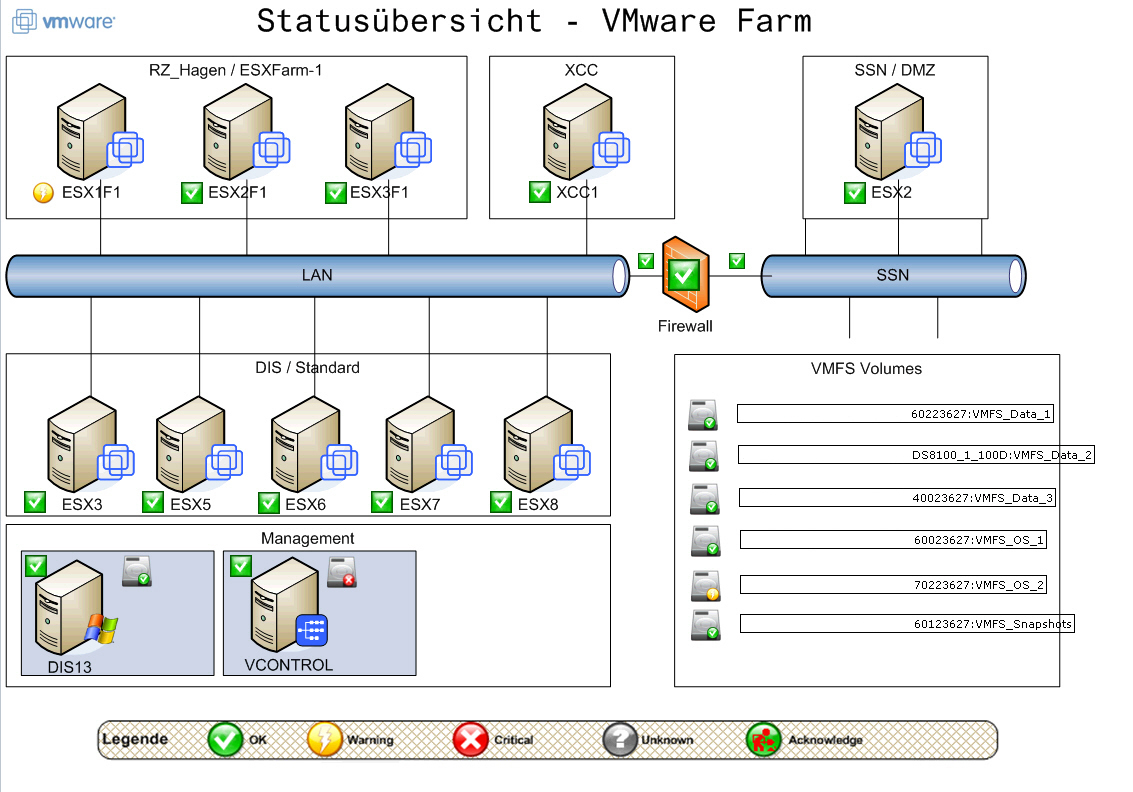
Di recente, durante uno dei miei controlli di routine presso la rete di un cliente, mi sono accorto che il proxy ivi utilizzato (Squid) mandava in timeout tutte le richieste HTTP/HTTPS dirette al sito paypal.com.
 Ora, premesso che esistono diversi modi per fare un po’ di debug sul proxy, utilizzando ad esempio dei tool sviluppati ad hoc (uno su tutti squidclient), ho preferito adoperare semplicemente cURL, fondamentalmente per 3 motivi:
Ora, premesso che esistono diversi modi per fare un po’ di debug sul proxy, utilizzando ad esempio dei tool sviluppati ad hoc (uno su tutti squidclient), ho preferito adoperare semplicemente cURL, fondamentalmente per 3 motivi:
1) la sua semplicità di impiego;
2) l’ottima documentazione a corredo;
3) la possibilità di visualizzare gli header HTTP di ciascuna richiesta (tracciando eventuali redirect).
Ma bando alle ciance ed ecco come ho individuato (e risolto) l’anomalia riscontrata.
Test di funzionamento
Per prima cosa ho effettuato 2 differenti richieste: la prima diretta ad http://www.paypal.com e la seconda verso http://paypal.com, avvalendomi, rispettivamente, delle flag -v (verbose), -k (per ignorare eventuali problemi di certificati SSL/TLS), -x (per definire il proxy da utilizzare) e – L (che mi permette di indicare il sito target della richiesta). Per http://www.paypal.com ho ottenuto:
root@linux-box:~# curl -v -k -x http://192.168.10.1:3128 -L http://www.paypal.com
* About to connect() to proxy 192.168.10.1 port 3128 (#0)
* Trying 192.168.10.1... connected
> GET http://www.paypal.com HTTP/1.1
> User-Agent: curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3
> Host: www.paypal.com
> Accept: */*
> Proxy-Connection: Keep-Alive
>
* HTTP 1.0, assume close after body
< HTTP/1.0 302 Moved Temporarily
< Date: Tue, 21 Feb 2017 08:16:33 GMT
< Server: Apache
< Location: https://192.168.10.1/block.html
< Vary: Accept-Encoding
< Content-Length: 214
< Content-Type: text/html; charset=iso-8859-1
< X-Cache: MISS from localhost
< X-Cache-Lookup: MISS from localhost:3128
< Via: 1.0 localhost (squid/3.1.19)
* HTTP/1.0 connection set to keep alive!
< Connection: keep-alive
<
* Ignoring the response-body
* Connection #0 to host 192.168.10.1 left intact
* Issue another request to this URL: 'https://192.168.10.1/block.html'
* About to connect() to proxy 192.168.10.1 port 3128 (#1)
* Trying 192.168.10.1... connected
* Establish HTTP proxy tunnel to 192.168.10.1:443
> CONNECT 192.168.10.1:443 HTTP/1.1
> Host: 192.168.10.1:443
> User-Agent: curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3
> Proxy-Connection: Keep-Alive
>
< HTTP/1.0 200 Connection established
<
* Proxy replied OK to CONNECT request
* successfully set certificate verify locations:
* CAfile: none
CApath: /*/*/certs
* SSLv3, TLS handshake, Client hello (1):
* SSLv3, TLS handshake, Server hello (2):
* SSLv3, TLS handshake, CERT (11):
* SSLv3, TLS handshake, Server key exchange (12):
* SSLv3, TLS handshake, Server finished (14):
* SSLv3, TLS handshake, Client key exchange (16):
* SSLv3, TLS change cipher, Client hello (1):
* SSLv3, TLS handshake, Finished (20):
* SSLv3, TLS change cipher, Client hello (1):
* SSLv3, TLS handshake, Finished (20):
* SSL connection using ECDHE-RSA-AES256-GCM-SHA384
* Server certificate:
* subject: C=IT; ST=Some-State; L=Roma; O=Test; CN=Test; emailAddress=hidden@email.it
* start date: 2013-02-25 15:48:44 GMT
* expire date: 2014-02-25 15:48:44 GMT
* issuer: C=IT; ST=Some-State; L=Roma; O=Test; CN=Test; emailAddress=hidden@email.it
* SSL certificate verify result: self signed certificate (18), continuing anyway.
> GET /block.html HTTP/1.0
> User-Agent: curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3
> Host: 192.168.10.1
> Accept: */*
>
< HTTP/1.1 200 OK
< Date: Tue, 21 Feb 2017 08:16:33 GMT
< Server: Apache
< Last-Modified: Mon, 25 Feb 2013 16:13:19 GMT
< ETag: "f293-289-4d68ed1c4eeb4"
< Accept-Ranges: bytes
< Content-Length: 649
< Vary: Accept-Encoding
< Connection: close
< Content-Type: text/html
<
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>Proibito</title>
</head>
<body>
<p align="center"><img src="http://192.168.10.1/images/forbidden.png" alt="forbidden" vspace="100"/></p>
<p align="center"><strong>I contenuti del sito sono stati bloccati per ragioni di sicurezza. Per maggiori informazioni contattare l'amministratore</strong></p>
</body>
</html>
* Closing connection #1
* SSLv3, TLS alert, Client hello (1):
* Closing connection #0
mentre per http://paypal.com l’output è stato il seguente:
root@linux-box:~# curl -v -k -x http://192.168.10.1:3128 -L http://paypal.com
* About to connect() to proxy 192.168.10.1 port 3128 (#0)
* Trying 192.168.10.1... connected
> GET http://paypal.com HTTP/1.1
> User-Agent: curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3
> Host: paypal.com
> Accept: */*
> Proxy-Connection: Keep-Alive
>
* HTTP 1.0, assume close after body
< HTTP/1.0 302 Moved Temporarily
< Date: Tue, 21 Feb 2017 08:17:36 GMT
< Server: Apache
< Location: https://192.168.10.1/block.html
< Vary: Accept-Encoding
< Content-Length: 214
< Content-Type: text/html; charset=iso-8859-1
< X-Cache: MISS from localhost
< X-Cache-Lookup: MISS from localhost:3128
< Via: 1.0 localhost (squid/3.1.19)
* HTTP/1.0 connection set to keep alive!
< Connection: keep-alive
<
* Ignoring the response-body
* Connection #0 to host 192.168.10.1 left intact
* Issue another request to this URL: 'https://192.168.10.1/block.html'
* About to connect() to proxy 192.168.10.1 port 3128 (#1)
* Trying 192.168.10.1... connected
* Establish HTTP proxy tunnel to 192.168.10.1:443
> CONNECT 192.168.10.1:443 HTTP/1.1
> Host: 192.168.10.1:443
> User-Agent: curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3
> Proxy-Connection: Keep-Alive
>
< HTTP/1.0 200 Connection established
<
* Proxy replied OK to CONNECT request
* successfully set certificate verify locations:
* CAfile: none
CApath: /*/*/certs
* SSLv3, TLS handshake, Client hello (1):
* SSLv3, TLS handshake, Server hello (2):
* SSLv3, TLS handshake, CERT (11):
* SSLv3, TLS handshake, Server key exchange (12):
* SSLv3, TLS handshake, Server finished (14):
* SSLv3, TLS handshake, Client key exchange (16):
* SSLv3, TLS change cipher, Client hello (1):
* SSLv3, TLS handshake, Finished (20):
* SSLv3, TLS change cipher, Client hello (1):
* SSLv3, TLS handshake, Finished (20):
* SSL connection using ECDHE-RSA-AES256-GCM-SHA384
* Server certificate:
* subject: C=IT; ST=Some-State; L=Roma; O=Test; CN=Test; emailAddress=hidden@email.it
* start date: 2013-02-25 15:48:44 GMT
* expire date: 2014-02-25 15:48:44 GMT
* issuer: C=IT; ST=Some-State; L=Roma; O=Test; CN=Test; emailAddress=hidden@email.it
* SSL certificate verify result: self signed certificate (18), continuing anyway.
> GET /block.html HTTP/1.0
> User-Agent: curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3
> Host: 192.168.10.1
> Accept: */*
>
< HTTP/1.1 200 OK
< Date: Tue, 21 Feb 2017 08:17:36 GMT
< Server: Apache
< Last-Modified: Mon, 25 Feb 2013 16:13:19 GMT
< ETag: "f293-289-4d68ed1c4eeb4"
< Accept-Ranges: bytes
< Content-Length: 649
< Vary: Accept-Encoding
< Connection: close
< Content-Type: text/html
<
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>Proibito</title>
</head>
<body>
<p align="center"><img src="http://192.168.10.1/images/forbidden.png" alt="forbidden" vspace="100"/></p>
<p align="center"><strong>I contenuti del sito sono stati bloccati per ragioni di sicurezza. Per maggiori informazioni contattare l'amministratore</strong></p>
</body>
</html>
* Closing connection #1
* SSLv3, TLS alert, Client hello (1):
* Closing connection #0
Individuazione della causa di malfuzionamento
In entrambi i casi il proxy mi ha reindirizzato alla pagina di notifica di squidGuard, ovvero il software che si occupa del filtraggio dei siti Web. Ciò ha fatto scattare un campanello di allarme nella mia testa, in quanto entrambi i domini dovrebbero essere già consentiti, ragion per cui ho deciso di indagare ulteriormente analizzando i log delle blacklist di squidGuard:
root@linux-box:/var/log/squid# tail -f spyware.log
2017-02-21 09:57:06 [1636] Request(default/spyware/-) http://www.paypal.com/ 192.168.10.1/proxy - GET REDIRECT
Una volta individuata la blacklist di interesse (ovvero spyware) ho focalizzato alla mia attenzione sul file domains, andando alla ricerca di tutte le stringhe contenenti paypal.com. Così facendo, una entry ha subito destato in me qualche sospetto, ovvero:
-paypal.com
che ho prontamente sostituito con:
\-paypal.com
aggiungendo semplicemente il carattere di escape (\) davanti al carattere –.
Ho quindi ricompilato le blacklist, settando i dovuti permessi e ricaricando la configurazione di Squid proxy:
root@linux-box:~# squidGuard -d -C all
root@linux-box:~# chown proxy:proxy -R /var/lib/squidguard/db
root@linux-box:~# squid3 -k reconfigure
A questo punto ho lanciato una nuova richiesta verso http://paypal.com, proprio per sincerarmi che la entry errata contenuta nel file domains fosse proprio quella modificata in precedenza:
root@linux-box:/var/lib/squidguard/db/spyware# curl -v -k -x http://192.168.10.1:3128 -L http://paypal.com/
* About to connect() to proxy 192.168.10.1 port 3128 (#0)
* Trying 192.168.10.1... connected
> GET http://paypal.com/ HTTP/1.1
> User-Agent: curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3
> Host: paypal.com
> Accept: */*
> Proxy-Connection: Keep-Alive
>
* HTTP 1.0, assume close after body
< HTTP/1.0 302 Moved Temporarily
< Date: Tue, 21 Feb 2017 10:06:48 GMT
< Location: https://paypal.com/
< Server: BigIP
< Content-Length: 0
< X-Cache: MISS from localhost
< X-Cache-Lookup: MISS from localhost:3128
< Via: 1.0 localhost (squid/3.1.19)
* HTTP/1.0 connection set to keep alive!
< Connection: keep-alive
<
* Connection #0 to host 192.168.10.1 left intact
* Issue another request to this URL: 'https://paypal.com/'
* About to connect() to proxy 192.168.10.1 port 3128 (#1)
* Trying 192.168.10.1... connected
* Establish HTTP proxy tunnel to paypal.com:443
> CONNECT paypal.com:443 HTTP/1.1
> Host: paypal.com:443
> User-Agent: curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3
> Proxy-Connection: Keep-Alive
>
< HTTP/1.0 200 Connection established
<
* Proxy replied OK to CONNECT request
* successfully set certificate verify locations:
* CAfile: none
CApath: /etc/ssl/certs
* SSLv3, TLS handshake, Client hello (1):
* SSLv3, TLS handshake, Server hello (2):
* SSLv3, TLS handshake, CERT (11):
* SSLv3, TLS handshake, Server finished (14):
* SSLv3, TLS handshake, Client key exchange (16):
* SSLv3, TLS change cipher, Client hello (1):
* SSLv3, TLS handshake, Finished (20):
* SSLv3, TLS change cipher, Client hello (1):
* SSLv3, TLS handshake, Finished (20):
* SSL connection using AES256-GCM-SHA384
* Server certificate:
* subject: C=US; ST=California; L=San Jose; O=PayPal, Inc.; OU=PayPal Production; CN=paypal.com
* start date: 2016-11-04 00:00:00 GMT
* expire date: 2018-11-01 12:00:00 GMT
* issuer: C=US; O=DigiCert Inc; OU=www.digicert.com; CN=DigiCert SHA2 High Assurance Server CA
* SSL certificate verify ok.
> GET / HTTP/1.0
> User-Agent: curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3
> Host: paypal.com
> Accept: */*
>
* HTTP 1.0, assume close after body
< HTTP/1.0 301 Moved Permanently
< Location: https://www.paypal.com/
< Strict-Transport-Security: max-age=63072000
< Connection: close
< Content-Length: 0
<
* Closing connection #1
* SSLv3, TLS alert, Client hello (1):
* Issue another request to this URL: 'https://www.paypal.com/'
* About to connect() to proxy 192.168.10.1 port 3128 (#1)
* Trying 192.168.10.1... connected
* Establish HTTP proxy tunnel to www.paypal.com:443
> CONNECT www.paypal.com:443 HTTP/1.1
> Host: www.paypal.com:443
> User-Agent: curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3
> Proxy-Connection: Keep-Alive
>
< HTTP/1.0 200 Connection established
<
* Proxy replied OK to CONNECT request
* successfully set certificate verify locations:
* CAfile: none
CApath: /etc/ssl/certs
* SSLv3, TLS handshake, Client hello (1):
* SSLv3, TLS handshake, Server hello (2):
* SSLv3, TLS handshake, CERT (11):
* SSLv3, TLS handshake, Server key exchange (12):
* SSLv3, TLS handshake, Server finished (14):
* SSLv3, TLS handshake, Client key exchange (16):
* SSLv3, TLS change cipher, Client hello (1):
* SSLv3, TLS handshake, Finished (20):
* SSLv3, TLS change cipher, Client hello (1):
* SSLv3, TLS handshake, Finished (20):
* SSL connection using ECDHE-RSA-AES128-GCM-SHA256
* Server certificate:
* subject: 1.3.6.1.4.1.311.60.2.1.3=US; 1.3.6.1.4.1.311.60.2.1.2=Delaware; businessCategory=Private Organization; serialNumber=3014267; C=US; postalCode=95131-2021; ST=California; L=San Jose; street=2211 N 1st St; O=PayPal, Inc.; OU=CDN Support; CN=www.paypal.com
* start date: 2016-02-02 00:00:00 GMT
* expire date: 2017-10-30 23:59:59 GMT
* issuer: C=US; O=Symantec Corporation; OU=Symantec Trust Network; CN=Symantec Class 3 EV SSL CA - G3
* SSL certificate verify ok.
> GET / HTTP/1.0
> User-Agent: curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3
> Host: www.paypal.com
> Accept: */*
>
* HTTP 1.0, assume close after body
< HTTP/1.0 302 Moved Temporarily
< Server: Apache
< X-Recruiting: If you are reading this, maybe you should be working at PayPal instead! Check out https://www.paypal.com/us/webapps/mpp/paypal-jobs
< Paypal-Debug-Id: c075f46342370
< Cache-Control: no-cache
< X-Content-Type-Options: nosniff
< X-XSS-Protection: 1; mode=block
< X-FRAME-OPTIONS: SAMEORIGIN
< Content-Security-Policy: default-src 'self' https://*.paypal.com https://*.paypalobjects.com https://nexus.ensighten.com 'unsafe-inline'; frame-src 'self' https://*.brighttalk.com https://*.paypal.com https://*.paypalobjects.com https://www.youtube.com/embed/ https://www.paypal-donations.com https://www.paypal-donations.co.uk https://*.qa.missionfish.org https://www.youtube-nocookie.com https://www.xoom.com https://*.pub.247-inc.net/; script-src 'self' https://*.brighttalk.com https://*.paypal.com https://*.paypalobjects.com https://www.youtube.com/iframe_api https://s.ytimg.com/yts/jsbin/ https://*.t.eloqua.com https://img.en25.com/i/elqCfg.min.js https://nexus.ensighten.com/ 'unsafe-inline' 'unsafe-eval'; connect-src 'self' https://*.paypal.com https://*.paypalobjects.com https://*.salesforce.com https://*.force.com https://*.eloqua.com https://nexus.ensighten.com https://storelocator.api.where.com https://api.paypal-retaillocator.com https://nominatim.openstreetmap.org https://www.paypal-biz.com; img-src 'self' * data:; object-src 'self' https://*.paypal.com https://*.paypalobjects.com; font-src 'self' https://*.paypalobjects.com;
< HTTP_X_PP_AZ_LOCATOR: slcb.slc
< Paypal-Debug-Id: c075f46342370
< Location: /it/home
< Content-Encoding: gzip
< Cache-Control: max-age=0, no-cache, no-store, must-revalidate
< Pragma: no-cache
< Content-Type: text/plain; charset=utf-8
< DC: phx-origin-www-1.paypal.com
< Content-Length: 56
< X-EdgeConnect-MidMile-RTT: 3
< X-EdgeConnect-Origin-MEX-Latency: 198
< X-EdgeConnect-MidMile-RTT: 169
< X-EdgeConnect-Origin-MEX-Latency: 198
< Date: Tue, 21 Feb 2017 10:06:51 GMT
< Connection: close
< Set-Cookie: LANG=it_IT%3BIT; Domain=.paypal.com; Path=/; Expires=Tue, 21 Feb 2017 18:52:46 GMT; HttpOnly
< Set-Cookie: tsrce=mppnodeweb; Domain=.paypal.com; Path=/; Expires=Wed, 22 Feb 2017 10:06:50 GMT; HttpOnly; Secure
< Set-Cookie: x-pp-s=eyJ0IjoiMTQ4NzY3MTYxMTM5NCIsIm0iOiIwIn0; Domain=.paypal.com; Path=/; HttpOnly; Secure
< Set-Cookie: nsid=s%3AUhjv0IeCf2Lsd4mAbdfaZCowZwbnEoLG.VPNYMobMlVf8MPI4EqbaGJHWsctx9knCbLdeDqVeGhg; Path=/; HttpOnly; Secure
< Set-Cookie: X-PP-SILOVER=name%3DLIVE3.WEB.1%26silo_version%3D880%26app%3Dmppnodeweb%26TIME%3D991013976%26HTTP_X_PP_AZ_LOCATOR%3Dslcb.slc; Expires=Tue, 21 Feb 2017 10:36:51 GMT; domain=.paypal.com; path=/; Secure; HttpOnly
< Set-Cookie: X-PP-SILOVER=; Expires=Thu, 01 Jan 1970 00:00:01 GMT
< Set-Cookie: AKDC=phx-origin-www-1.paypal.com; expires=Tue, 21-Feb-2017 10:36:51 GMT; path=/; secure
< Set-Cookie: akavpau_ppsd=1487672211~id=cae8071e8da0e5fdb485811908c64fd0; path=/
< Strict-Transport-Security: max-age=63072000
<
* Closing connection #1
* SSLv3, TLS alert, Client hello (1):
* Issue another request to this URL: 'https://www.paypal.com/it/home'
* About to connect() to proxy 192.168.10.1 port 3128 (#1)
* Trying 192.168.10.1... connected
* Establish HTTP proxy tunnel to www.paypal.com:443
> CONNECT www.paypal.com:443 HTTP/1.1
> Host: www.paypal.com:443
> User-Agent: curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3
> Proxy-Connection: Keep-Alive
>
< HTTP/1.0 200 Connection established
<
* Proxy replied OK to CONNECT request
* successfully set certificate verify locations:
* CAfile: none
CApath: /etc/ssl/certs
* SSL re-using session ID
* SSLv3, TLS handshake, Client hello (1):
* SSLv3, TLS handshake, Server hello (2):
* SSLv3, TLS change cipher, Client hello (1):
* SSLv3, TLS handshake, Finished (20):
* SSLv3, TLS change cipher, Client hello (1):
* SSLv3, TLS handshake, Finished (20):
* SSL connection using ECDHE-RSA-AES128-GCM-SHA256
* Server certificate:
* subject: 1.3.6.1.4.1.311.60.2.1.3=US; 1.3.6.1.4.1.311.60.2.1.2=Delaware; businessCategory=Private Organization; serialNumber=3014267; C=US; postalCode=95131-2021; ST=California; L=San Jose; street=2211 N 1st St; O=PayPal, Inc.; OU=CDN Support; CN=www.paypal.com
* start date: 2016-02-02 00:00:00 GMT
* expire date: 2017-10-30 23:59:59 GMT
* issuer: C=US; O=Symantec Corporation; OU=Symantec Trust Network; CN=Symantec Class 3 EV SSL CA - G3
* SSL certificate verify ok.
> GET /it/home HTTP/1.0
> User-Agent: curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3
> Host: www.paypal.com
> Accept: */*
>
* HTTP 1.0, assume close after body
< HTTP/1.0 200 OK
< Server: Apache
< X-Recruiting: If you are reading this, maybe you should be working at PayPal instead! Check out https://www.paypal.com/us/webapps/mpp/paypal-jobs
< Paypal-Debug-Id: ef6f606ac62a4
< Cache-Control: no-cache
< X-Content-Type-Options: nosniff
< X-XSS-Protection: 1; mode=block
< X-FRAME-OPTIONS: SAMEORIGIN
< Content-Security-Policy: default-src 'self' https://*.paypal.com https://*.paypalobjects.com https://nexus.ensighten.com 'unsafe-inline'; frame-src 'self' https://*.brighttalk.com https://*.paypal.com https://*.paypalobjects.com https://www.youtube.com/embed/ https://www.paypal-donations.com https://www.paypal-donations.co.uk https://*.qa.missionfish.org https://www.youtube-nocookie.com https://www.xoom.com https://*.pub.247-inc.net/; script-src 'self' https://*.brighttalk.com https://*.paypal.com https://*.paypalobjects.com https://www.youtube.com/iframe_api https://s.ytimg.com/yts/jsbin/ https://*.t.eloqua.com https://img.en25.com/i/elqCfg.min.js https://nexus.ensighten.com/ 'unsafe-inline' 'unsafe-eval'; connect-src 'self' https://*.paypal.com https://*.paypalobjects.com https://*.salesforce.com https://*.force.com https://*.eloqua.com https://nexus.ensighten.com https://storelocator.api.where.com https://api.paypal-retaillocator.com https://nominatim.openstreetmap.org https://www.paypal-biz.com; img-src 'self' * data:; object-src 'self' https://*.paypal.com https://*.paypalobjects.com; font-src 'self' https://*.paypalobjects.com;
< ETag: W/"6646-N9seUapd2xMK7C+gFi/cTw"
< HTTP_X_PP_AZ_LOCATOR: dcg11.slc
< Paypal-Debug-Id: ef6f606ac62a4
< Cache-Control: max-age=0, no-cache, no-store, must-revalidate
< Pragma: no-cache
< Content-Type: text/html; charset=utf-8
< DC: phx-origin-www-1.paypal.com
< X-EdgeConnect-MidMile-RTT: 3
< X-EdgeConnect-Origin-MEX-Latency: 242
< X-EdgeConnect-MidMile-RTT: 175
< X-EdgeConnect-Origin-MEX-Latency: 242
< Date: Tue, 21 Feb 2017 10:06:54 GMT
< Content-Length: 26182
< Connection: close
< Set-Cookie: cookie_check=yes; Domain=.paypal.com; Path=/; Expires=Sun, 21 Feb 2027 10:06:52 GMT; HttpOnly; Secure
< Set-Cookie: LANG=it_IT%3BIT; Domain=.paypal.com; Path=/; Expires=Tue, 21 Feb 2017 18:52:48 GMT; HttpOnly
< Set-Cookie: tsrce=mppnodeweb; Domain=.paypal.com; Path=/; Expires=Wed, 22 Feb 2017 10:06:52 GMT; HttpOnly; Secure
< Set-Cookie: x-pp-s=eyJ0IjoiMTQ4NzY3MTYxMzk0NyIsIm0iOiIwIn0; Domain=.paypal.com; Path=/; HttpOnly; Secure
< Set-Cookie: nsid=s%3A74ujkGU9eWQSC2wQM8PXHRRoHjuQmucM.0ykPY%2FAkmfXl50QcbBuCSwC7lEm1YbqKWOXxw4FicY0; Path=/; HttpOnly; Secure
< Set-Cookie: X-PP-SILOVER=name%3DLIVE3.WEB.1%26silo_version%3D880%26app%3Dmppnodeweb%26TIME%3D1024568408%26HTTP_X_PP_AZ_LOCATOR%3Ddcg11.slc; Expires=Tue, 21 Feb 2017 10:36:53 GMT; domain=.paypal.com; path=/; Secure; HttpOnly
< Set-Cookie: X-PP-SILOVER=; Expires=Thu, 01 Jan 1970 00:00:01 GMT
< Set-Cookie: AKDC=phx-origin-www-1.paypal.com; expires=Tue, 21-Feb-2017 10:36:54 GMT; path=/; secure
< Set-Cookie: akavpau_ppsd=1487672214~id=56a8294899d3c18083d0709205e7d737; path=/
< Strict-Transport-Security: max-age=63072000
<
<
richiesta che è andata a buon fine, per la causa del problema è stata correttamente individuata.
Soluzione definitiva
Per risolvere definitivamente tale anomalia (legata principalmente alla cattiva gestione, da parte di squidGuard, dei domini che contengono caratteri particolari), ho deciso di agire come segue. Poichè le blackist vengono aggiornate ogni notte in modo automatico, il file domains modificato in precedenza verrebbe continuamente sovrascritto, rendendo nulla la sostituzione di -paypal.com com con \-paypal.com. Quindi, per fare in modo che squidGuard torni a consentire definitivamente l’accesso al dominio paypal.com (e relativi sottodomini), ho deciso di creare un file domains all’interno della dir /var/lib/squidguard/db/whitelist, contenente la entry paypal.com:
root@linux-box:~# cat /var/lib/squidguard/db/whitelist/domains
paypal.com
Ho quindi modificato la configurazione di squidGuard (/etc/squid/squidGuard.conf), ridefinendo la sequenza di matching dell’ACL che si occupa del filtraggio:
acl {
default {
pass whitelist !aggressive !drugs !gambling !hacking !porn !proxy !redirector !spyware !suspect !violence !warez !custom
redirect http://192.168.10.1/block.html
}
Nella fattispecie, ho fatto in modo che venissero dapprima consentiti tutti i domini in whitelist, bloccati i domini presenti nelle blacklist ed infine consentiti tutti gli altri.
Ho quindi ricompilato le blacklist di squidGuard come visto in precedenza:
root@linux-box:~# squidGuard -d -C all
root@linux-box:~# chown proxy:proxy -R /var/lib/squidguard/db
root@linux-box:~# squid3 -k reconfigure
ed il problema è stato definitivamente risolto.
Alla prossima.