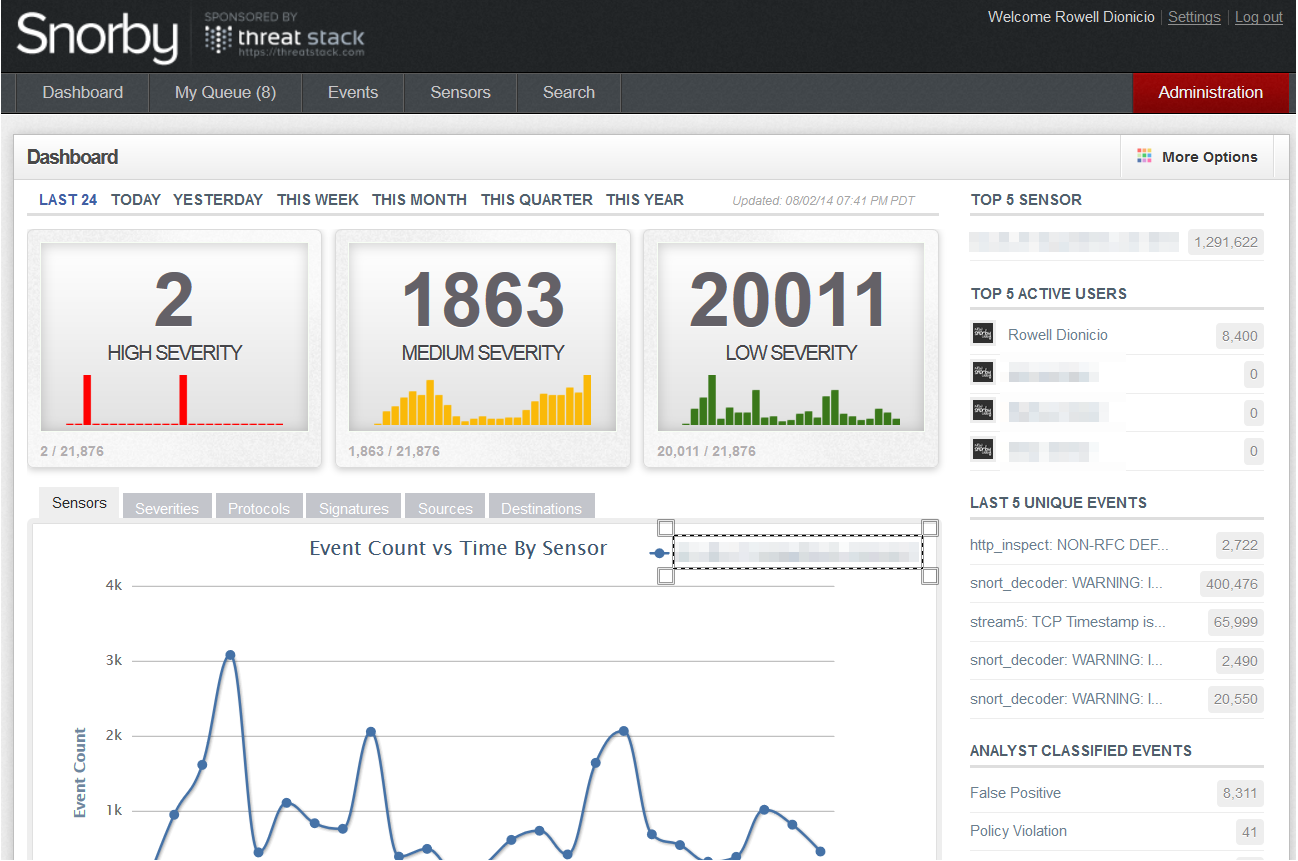
In questo post ho mostrato come configurare il software che funge da sensore, ovvero snort. Adesso vedremo come installare e configurare pulledpork (che si occuperà dell’aggiornamento delle firme) e barnyard2 (per il salvataggio degli allarmi all’interno di un DB).
 Installazione e configurazione di pulledpork
Installazione e configurazione di pulledpork
Per prima cosa occorre installare i prerequisiti, ovvero perl-libwww-perl perl-Crypt-SSLeay e perl-Archive-Tar:
yum -y install perl-libwww-perl perl-Crypt-SSLeay perl-Archive-Tar
Posizioniamoci nella dir /usr/local/src e scarichiamo l’applicativo in questione (scritto in Perl):
wget https://pulledpork.googlecode.com/files/pulledpork-0.7.0.tar.gz
per poi scompattare l’archivio, rendere lo scrip eseguibile e copiarlo all’interno di /usr/sbin (assegnandogli i giusti privilegi):
tar -xvf pulledpork-0.7.0.tar.gz
cd pulledpork-0.7.0
chmod +x pulledpork.pl
cp pulledpork.pl /usr/sbin
chmod 755 /usr/sbin/pulledpork.pl
A questo punto possiamo copiare i file *.conf (presenti nella directory etc) all’interno di /etc/snort, con il successivo editing dei permessi:
cd etc
cp * /etc/snort
chown -R snort:snort /etc/snort
Ora modifichiamo il contenuto del file /etc/snort/pulledpork.conf, apportando le seguenti modifiche:
snort_path=/usr/sbin/snort
config_path=/etc/snort/snort.conf
distro=Centos-5-4
rule_path=/etc/snort/rules/snort.rules
out_path=/etc/snort/rules/
sid_msg=/etc/snort/sid-msg.map
black_list=/etc/snort/rules/black_list.rules
#IPRVersion=/usr/local/etc/snort/rules/iplists
enablesid=/etc/snort/enablesid.conf
dropsid=/etc/snort/dropsid.conf
disablesid=/etc/snort/disablesid.conf
modifysid=/etc/snort/modifysid.conf
rule_url=https://www.snort.org/reg-rules/|snortrules-snapshot-2975.tar.gz|<vostro oinkcode>
rule_url=https://s3.amazonaws.com/snort-org/www/rules/community/|community-rules.tar.gz|Community
rule_url=http://labs.snort.org/feeds/ip-filter.blf|IPBLACKLIST|open
rule_url=https://www.snort.org/reg-rules/|opensource.gz|<vostro oinkcode>
Da notare che ho commentato la direttiva IPRVersion ed ho scelto un nome specifico per le blacklist (ovvero black_list.rules), in quando devono essere differenziate da quelle utilizzate da snort (reputation preprocessor). Per la precisione, il file black_list.rules non è altro che una lista piatta di indirizzi IP, a differenza del file blacklist.rules che possiede il tipico formato delle regole di snort (ad esempio alert tcp $HOME_NET any -> $EXTERNAL_NET $HTTP_PORTS).
Testiamo adesso la configurazione di pulledpork mediante il comando:
pulledpork.pl -vv -c /etc/snort/pulledpork.conf -T -l
e se il relativo output contiene la stringa:
Fly Piggy Fly!
vuol dire che il suddetto applicativo sta funzionando correttamente. Creaiamo un task su crontab per eseguire l’update delle firme ogni notte:
nano /etc/crontab
il cui contenuto dovrà essere:
00 04 * * * root /usr/sbin/pulledpork.pl -c /etc/snort/pulledpork.conf && /sbin/service snortd restart
e passiamo alla configurazione di barnyard2.
Installazione e configurazione di barnyard2
Prima di cominciare occorre fare una premessa: il file di configurazione che daremo in pasto a barnyard2 può riferirsi ad una sola interfaccia. Ciò significa che dovremo creare un file di configurazione specifico per ciascuna interfaccia su cui i sensori (le istanze di snort) sono in ascolto, in modo tale che il loro output possa essere parsato (in modo indipendente) dalle due istanze distinte di barnyard2.
Come al solito, il primo step consiste nell’installazione del software necessario per la compilazione del suddetto applicativo:
yum install libtool
e successivamente, dopo esserci posizionati nella directory /usr/local/src, possiamo scaricare i sorgenti:
cd /usr/local/src
git clone git://github.com/firnsy/barnyard2.git
Compiliamo ed installiamo:
cd barnyard2
./autogen.sh
./configure --with-mysql --with-mysql-libraries=/usr/lib64/mysql/
make
make install
copiamo il file di configurazione di barnyard2 all’interno della directory /etc/snort
cp etc/barnyard2.conf /etc/snort
e modifichiamolo in base alle nostre esigenze:
config logdir: /var/log/snort
config interface: eth0
config daemon
input unified2
output alert_full
config waldo_file: /var/log/snort/eth0/barnyard2-log.waldo
output log_tcpdump: tcpdump.log
output database: log, mysql, user=<vostrouser> password=<vostrapassword> dbname=snorby host=localhost
copiamo il suddetto file in barnyard2-eth0.conf ed in barnyard2-eth1.conf:
cp /etc/snort/barnyard2.conf /etc/snort/barnyard2-eth0.conf
cp /etc/snort/barnyard2.conf /etc/snort/barnyard2-eth1.conf
Modifichiamo quest’ultimo sostituendo le diciture:
config interface: eth0
config waldo_file: /var/log/snort/eth0/barnyard2-log.waldo
con:
config interface: eth1
config waldo_file: /var/log/snort/eth1/barnyard2-log.wald
Inoltre, per fare in modo che le due istanze di barnyard2 vengano avviate come “demone”, ho modificato il file di startup presente nella dir rpm, dopo averlo copiato in /etc/init.d ed averlo reso eseguibile:
cp rpm/barnyard2 /etc/init.d
chmod +x /etc/init.d/barnyard2
Di seguito riporto il contenuto del suddetto file, in cui sono presenti le modifiche da me effettuate:
#!/bin/sh
#
# Init file for Barnyard2
#
#
# chkconfig: 2345 60 60
# description: Barnyard2 is an output processor for snort.
#
# processname: barnyard2
# config: /etc/sysconfig/barnyard2
# config: /etc/snort/barnyard.conf
# pidfile: /var/lock/subsys/barnyard2.pid
source /etc/rc.d/init.d/functions
source /etc/sysconfig/network
### Check that networking is up.
[ "${NETWORKING}" == "no" ] && exit 0
[ -x /usr/sbin/snort ] || exit 1
[ -r /etc/snort/snort.conf ] || exit 1
### Default variables
SYSCONFIG="/etc/sysconfig/barnyard2"
### Read configuration
[ -r "$SYSCONFIG" ] && source "$SYSCONFIG"
RETVAL=0
prog="barnyard2"
desc="Snort Output Processor"
start() {
echo -n $"Starting $desc ($prog): "
for INT in $INTERFACES; do
echo " "
echo "binding over $INT..."
ARCHIVEDIR="$SNORTDIR/$INT/archive"
WALDO_FILE="$SNORTDIR/$INT/barnyard2.waldo"
if [ $INT == 'eth0' ];then
BARNYARD_OPTS="-D -c $CONF1 -d $SNORTDIR/${INT} -w $WALDO_FILE -l $SNORTDIR/${INT} -a $ARCHIVEDIR -f $LOG_FILE $EXTRA_ARGS"
elif [ $INT == 'eth1' ];then
BARNYARD_OPTS="-D -c $CONF2 -d $SNORTDIR/${INT} -w $WALDO_FILE -l $SNORTDIR/${INT} -a $ARCHIVEDIR -f $LOG_FILE $EXTRA_ARGS"
fi
daemon $prog $BARNYARD_OPTS
done
RETVAL=$?
echo
[ $RETVAL -eq 0 ] && touch /var/lock/subsys/$prog
return $RETVAL
}
stop() {
echo -n $"Shutting down $desc ($prog): "
killproc $prog
RETVAL=$?
echo
[ $RETVAL -eq 0 ] && rm -f /var/run/barnyard2*
return $RETVAL
}
restart() {
stop
start
}
reload() {
echo -n $"Reloading $desc ($prog): "
killproc $prog -HUP
RETVAL=$?
echo
return $RETVAL
}
case "$1" in
start)
start
;;
stop)
stop
;;
restart)
restart
;;
reload)
reload
;;
condrestart)
[ -e /var/lock/subsys/$prog ] && restart
RETVAL=$?
;;
status)
status $prog
RETVAL=$?
;;
dump)
dump
;;
*)
echo $"Usage: $0 {start|stop|restart|reload|condrestart|status|dump}"
RETVAL=1
esac
exit $RETVAL
Il contenuto del file /etc/sysconfig/barnyard2 (in cui sono contenute le opzioni di avvio del demone) è, invece, il seguente:
LOG_FILE="snort.log"
SNORTDIR="/var/log/snort"
INTERFACES="eth0 eth1"
PIDPATH="/var/run"
CONF1=/etc/snort/barnyard2-eth0.conf
CONF2=/etc/snort/barnyard2-eth1.conf
EXTRA_ARGS="--pid-path /var/run"
Creiamo i file con estenzione *.waldo:
touch /var/log/snort/eth0/barnyard2-log.waldo
touch /var/log/snort/eth1/barnyard2-log.waldo
e facciamo in modo che il suddetto demone venga avviato in modo automatico dopo ogni riavvio della macchina:
chkconfig --add barnyard2
chkconfig barnyard2 on
Creaiamo ora il DB snorby (in cui barnyard2 dovrà salvare gli allarmi generati da snort) attraverso l’interfaccia a linea di comando di MySQL. I comandi da lanciare sono i seguenti:
create schema snorby;
grant all on snorby.* to vostrouser@localhost;
set password for vostrouser@localhost=password('vostrapassword');
use snorby;
source /usr/local/src/barnyard2/schemas/create_mysql
flush privileges;
exit
Prima di avviare il suddetto demone, occorre verificare che la sua priorità di avvio minore rispetto a quella di MySQL (valori bassi corrispondono a priorità alte). Infatti, in caso contrario, barnyard2 tenterà di parlare (via file mysql.sock) con il DBMS in questione, cosa impossibile nel caso in cui MySQL non sia ancora avviato (restituendoci, molto banalmente, l’errore file not found). In particolare, all’interno del codice associato al demone barnyard2 (da me modificato), è presente una priorità di avvio pari a 60 (definita tramite la direttiva chkconfig), mentre, a titolo di cronaca, la priorità di avvio relativa al demone mysqld è pari a 49.
Verifichiamo che tutto funzioni correttamente mediante i comandi:
barnyard2 -c /etc/snort/barnyard2-eth0.conf -d /var/log/snort/eth0 -f snort.log -w /var/log/snort/barnyard2-log.waldo -D
e
barnyard2 -c /etc/snort/barnyard2-eth1.conf -d /var/log/snort/eth1 -f snort.log -w /var/log/snort/barnyard2-log.waldo -D
per poi avviare il demone vero e proprio:
service barnyard2 start
A demone avviato, come ulteriore verifica, possiamo collegarci al DB snorby e lanciare la query:
select count(*) from events;
e se il valore restituito è > 0 vuol dire che barnyard2 e snort stanno operando correttamente.
Per ora è tutto. Nel prossimo post vedremo come installare e configurare Snorby (la Web GUI).
 Eseguire tale operazione “a mano” può essere tedioso e soprattutto controproducente in termini di tempo. Come fare quindi? Semplice, realizzare uno scrip bash in grado di automatizzare tale attività.
Eseguire tale operazione “a mano” può essere tedioso e soprattutto controproducente in termini di tempo. Come fare quindi? Semplice, realizzare uno scrip bash in grado di automatizzare tale attività.