Uno dei target preferiti dagli script kiddie è il servizio Remote Desktop di Windows. Vi assicuro che, giornalmente, i tentativi di bruteforcing contro di esso possono superare (e anche di molto ) il centinaio. Proprio per questo motivo ho deciso di mettere in atto tutta una serie di accorgimenti in grado di limitare questa tipologia di attacco, basandomi principalmente su due strategie:
1) quella proattiva, grazie alla quale è possibile bloccare l’IP sorgente dei tentativi di intrusione;
2) quella passiva, basata sul monitoraggio in tempo reale degli eventi di Windows, con la generazione di alert ad hoc da parte dell’NMS (Nagios) nel caso in cui vi siano episodi di logon falliti.

Entrambe le suddette strategie si applicano a tutti i servizi attivi sulla macchina remota e che prevedono autenticazione (FTP, HTTP, ecc.), incluso, ovviamente, il Remote Desktop.
Ingredienti
I software necessari per l’hardening del servizio Remote Desktop sono i seguenti:
1) Il tool IPBan (che potete scaricare gratuitamente da qui), il quale è in grado di bannare l’IP sorgente degli attacchi dopo un determinato numero di tentativi di accesso falliti;
2) Il tool NSClient++ (anch’esso gratuito, lo si può scaricare da qui), nella versione 0.4.1.105 per architettura a 64 bit (la più recente tra quelle che non hanno problemi con il matching dei filtri sul monitoraggio degli eventi di Windows).
Lato NMS, invece, è necessario installare e configurare NSCA server, il quale rimarrà in ascolto sulla porta TCP 5667 nell’attesa che NSClient++ gli inoltri qualche evento (grazie all’applicativo NSCAClient). Una volta ricevuto l’evento, esso verrà dato in pasto a Nagios che, grazie ad un servizio di tipo passivo, genererà un allarme specifico in grado di ragguagliarci sul tentativo di accesso fallito.
Installazione e configurazione di IPBan
Prima di installare il suddetto tool è necessario configurare la macchina su cui è attivo Remote Desktop, operando mediante l’utility secpol.msc (Local Policy -> Security Options) ed impostando i seguenti parametri:
1) Network security: LAN Manager authentication level da settare su Send NTLMv2 response only. Refuse LM & NTLM
2) Network security: Restrict NTLM: Audit Incoming NTLM Traffic da impostare su Enable auditing for all accounts
3) Network security: Restrict NTLM: Incoming NTLM traffic da impostare su Deny all accounts
Inoltre, è necessario settare su Allow connections from computers running any version of Remote Desktop (less secure) il tab Remote delle impostazioni di sistema (vedi lo screenshot sottostante).
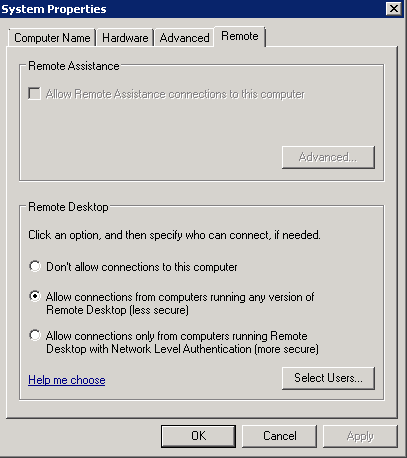
Tali direttive sono necessarie affinchè sul log degli eventi di Windows venga salvato l’indirizzo IP sorgente dell’attacco, in modo tale che IPBan possa riconoscerlo e quindi bloccarlo.
Una volta fatto ciò, estraiamo il contenuto del file IPBan.zip all’interno di C:\IPBan e lanciamo il prompt dei comandi con privilegi di amministratore, per poi digitare il seguente comando:
C:\IPBan> sc create IPBAN type= own start= auto binPath= C:\IPBan\ipban.exe DisplayName= IPBAN
il quale ci permetterà di creare un servizio apposito basato sul tool appena scaricato.
Inoltre, editiamo il suo file di configurazione (IPBan.exe.config), portando a 3 il numero massimo di tentativi di logon falliti prima del ban (tale valore, di default, è pari 5):
<!-- Number of failed audits in the event viewer before banning the ip address -->
<add key="FailedLoginAttemptsBeforeBan" value="3" />
Infine avviamo il servizio precedentemente creato:
C:\Users\Administrator>net start IPBAN
Installazione e configurazione di NSClient++
Come già detto in precedenza, il suddetto software ci consente di monitorare in tempo reale gli eventi di Windows, filtrandoli in modo opportuno.
Nel mio caso ho scelto di installare solo ed esclusivamente i plugin più comuni ed NSCAClient, il quale interagirà col nostro NMS.
Di seguito riporto uno screenshot esplicativo:
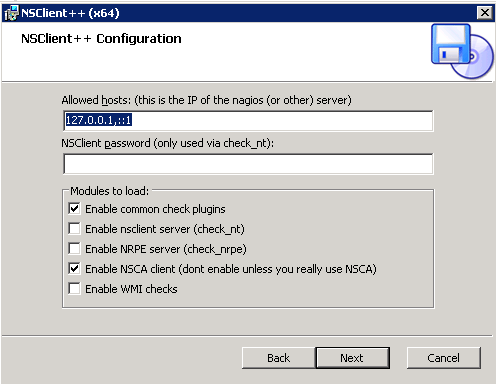
Una volta completata l’installazione si può procedere con la configurazione di NSClient++, editando il file nsclient.ini presente nella directory C:\Program Files\NSclient++ ed il cui contenuto dovrebbe essere simile al seguente:
# If you want to fill this file with all avalible options run the following command:
# nscp settings --generate --add-defaults --load-all
# If you want to activate a module and bring in all its options use:
# nscp settings --activate-module <MODULE NAME> --add-defaults
# For details run: nscp settings --help
; Undocumented section
[/settings/default]
; Undocumented key
password = vostrapassword
; Undocumented key
allowed hosts = 127.0.0.1,::1
; Undocumented section
[/modules]
;moduli da abilitare
CheckEventLog=1
NSCAClient = 1
[/settings/eventlog/real-time]
enabled=1
debug=1
log=Application,Security
destination=NSCA
startup age=30m
[/settings/eventlog/real-time/filters/logon-failed]
filter= id = 4625
severity= WARNING
[/settings/NSCA/client]
hostname=Server-Windows-RDP
[/settings/NSCA/client/targets/default]
address=nsca://indirizzoNMS:5667
encryption=3des
password=vostrapassword
In particolare, nella sezione [/modules] vengono specificati i moduli di NSClient++ da caricare, ovvero CheckEventLog ed NSCAClient (il primo serve per il monitoraggio in tempo reale degli eventi ed il secondo per l’inoltro degli stessi all’NMS).
Nella sezione [/settings/eventlog/real-time] vengono definiti i parametri generali per il monitoraggio degli eventi, tra cui i log di cui tenere traccia (Application e Security) ed a chi devono essere inoltrati (destination=NSCA). Inoltre, solo durante una prima fase di testing, è opportuno abilitare la modalità debug (debug=1), soprattutto per verificare il corretto funzionamento dei filtri da noi definiti.
Nella sezione [/settings/eventlog/real-time/filters/logon-failed] (dove logon-failed non è altro che il nome del servizio associato all’host da monitorare e presente nello specifico file di configurazione di Nagios) viene indicato il filtro da utilizzare per l’identificazione dell’evento (filter=ID = 4625, ovvero logon failure) e la severity dell’alert generato da Nagios (severity= WARNING).
In [/settings/NSCA/client] viene definito l’hostname del server da monitorare (hostname=Server-Windows-RDP), il quale deve coincidere con quello definito nel file di configurazione di Nagios.
Infine, in [/settings/NSCA/client/targets/default] vengono indicati i parametri di connessione al nostro NMS (su cui è attivo il server NSCA), quali URL (address=nsca://indirizzoNMS:5667), modalità di cicfratura simmetrica (encryption=3des) e password (password=vostrapassword). Da notare che, inizialmente, avevo scelto come metodo di cifratura AES256 lato client e RIJNDAEL-256 lato server, ma l’autenticazione falliva costantemente, ragion per cui ho dovuto optare per il triplo des.
Avviamo quindi il servizio nscp mediante il comando:
C:\Users\Administrator>net start nscp
e passiamo alla configurazione dell’NMS.
Installazione e configurazione di NSCA Server
La macchina su cui è attivo Nagios è una CentOS 6.4 a 64 bit ergo, per installare NSCA Server (nella sua ultima versione stabile, ovvero la 2.7.2), è sufficiente lanciare il comando:
[root@nms ~]# yum install nagios-nsca
Una volta installato, occorre configurarlo edintando il file /etc/nagios/nsca.cnf, il cui contenuto dovrà essere simile al seguente:
pid_file=/var/run/nsca.pid
server_port=5667
nsca_user=nagios
nsca_group=nagios
debug=1
command_file=/var/spool/nagios/cmd/nagios.cmd
alternate_dump_file=/var/spool/nagios/nsca.dump
aggregate_writes=0
append_to_file=0
max_packet_age=30
password=vostrapassword
decryption_method=3
Dove il decryption method 3 non è altro che il triplo des. Ovviamente, affinchè client e server possano “capirsi”, è necessario che decryption method e password coincidano su entrambi i fronti.
Infine, avviamo il servizio in questione digitando:
[root@nms ~]# service nsca start
Configurazione di Nagios
L’ultimo step consiste nella configurazione di un servizio di tipo passivo relativo all’host monitorato da Nagios. Editiamo quindi il file /etc/nagios/object/Server-Windows-RDP.cfg aggiungendo il servizio logon-failed, il quale avrà la seguente struttura:
define service{
use local-service
host_name Server-Windows-RDP
service_descripion logon-failed
check_command check_passive
passive_checks_enabled 1
active_checks_enabled 0
max_check_attempts 1
is_volatile 1
check_freshness 1
freshness_threshold 600
flap_detection_enabled 0
}
Ricarichiamo la configurazione del nostro NMS per rendere effettive le suddette modifiche:
[root@nms ~]# service nagios reload
ed abbiamo finito.
Considerazioni finali
Prima di chiedere il post occorre fare qualche precisazione:
1) Non sono un fan di NSCP, sia perchè vi sono continui cambi di sintassi tra minor release (soprattutto per ciò che concerne la definizione dei filtri) che per la presenza di qualche baco più o meno grave. Ad esempio, ho notato che nella versione 0.5.0, l’inserimento di record all’interno del log degli eventi di Windows (creati ad hoc mediante il comando nscp eventlog insert) non funziona (come alternativa ho dovuto utilizzare l’applet write-eventlog di PowerShell).
2) E’ necessario che la versione del client NSCA sia identica a quella del server, pena l’impossibilità di ricevere gli eventi (CRC error).
3) Sia lato client che lato server il payload massimo degli eventi è pari a 512 byte (limite superato abbondatemente nella versione unstable 2.9.1 e portato a 4096 byte). Ciò comporta la possibile perdita di parte dell’output (ovvero tutto ciò che eccede i 512 byte). Esiste comunque una direttiva (lato client) in grado di innalzare il suddetto limite (payload length), ma per farla funzionare è necessario modificare il contenuto della libreria common.h prima della compilazione da sorgente. Quest’ultima operazione risulta essere abbastanza semplice se si ha a che fare con i sorgenti *NIX (#define MAX_PLUGINOUTPUT_LENGTH 4096) ma molto più tediosa nel caso dei sorgenti Windows.
Il post termina qui.
Alla prossima.
 Definizione dei pool DHCP e della reservation
Definizione dei pool DHCP e della reservation