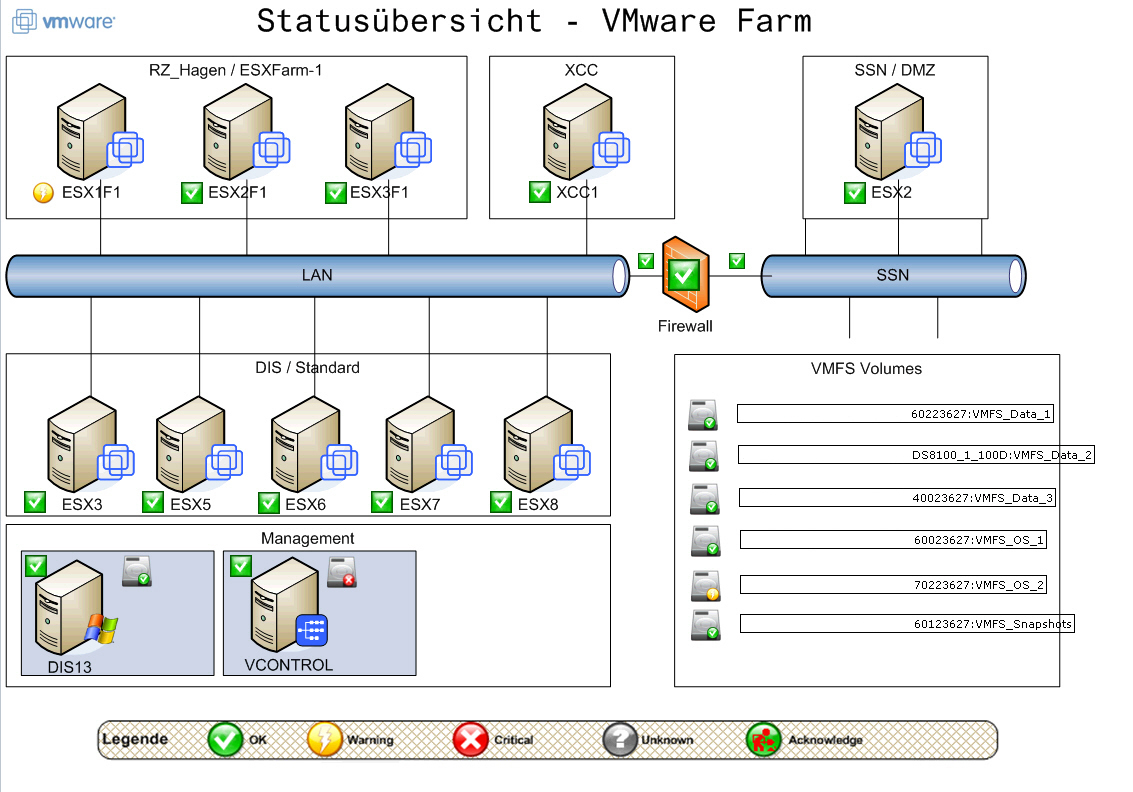
Partendo dalle considerazioni fatte in questo post, ho deciso di mettere a punto uno script bash da integrare a Nagios, in modo da monitorare lo status dei volumi RAID (e dei dischi fisici annessi) a prescindere dal metodo utilizzato per l’implementazione di tale tecnologia (hardware, fake oppure software).
 Di seguito riporto il suddetto script nella sua interezza:
Di seguito riporto il suddetto script nella sua interezza:
#!/bin/bash
type=$1
subtype=$2
element=$3
usage="check_raid <--software|--fake|--hardware> [--megaraid|--mpt] [--volume|--physical|--battery]"
if [[ ! -z "$type" && "$type" =~ "software" ]];then
okswraid=0;
koswraid=0;
volumes=`cat /proc/mdstat | grep md | grep active | grep -v inactive | awk '{print $1}' | wc -l`
if [[ ! -z $volumes ]];then
for (( v=1; v<=$volumes; v++ ))
do
volume=`cat /proc/mdstat | grep md | grep active | grep -v inactive | awk '{print $1}' | sed -n "$v p"`
raidtype=`cat /proc/mdstat | grep md | grep active | grep -v inactive | awk '{print $4}' | sed -n "$v p"`
diskno=`cat /proc/mdstat | grep '[[0-9]\/[0-9]]' | awk '{print $3}' | sed -n "$v p"`
disksok=`echo $diskno | sed 's/\[//g' | cut -d '/' -f1`
diskstotal=`echo $diskno | sed 's/\]//g' | cut -d '/' -f2`
if [[ "$disksok" -eq "$diskstotal" ]];then
echo "OK: Software RAID volume $volume configured in $raidtype is OK, with $diskno disks UP"
((okswraid++))
elif [[ "$disksok" -lt "$diskstotal" ]];then
echo "CRITICAL: Software RAID volume $volume configured in $raidtype is CRITICAL, with $diskno disks UP"
((koswraid++))
fi
done
if [[ $koswraid -eq 0 ]];then
exit 0;
else
exit 2;
fi
else
echo "UNKNOWN: No software RAID configured"
exit 3;
fi
elif [[ ! -z "$type" && "$type" =~ "fake" ]];then
bin=`/usr/bin/which dmraid`
if [[ ! -z $bin ]];then
result=`$bin -s`
disksno=`$bin -r | grep -v no | wc -l`
disksok=`$bin -r | grep ok | wc -l`
if [[ ! -z "$result" && "$result" =~ "ok" ]];then
echo "OK: RAID Status is OK, with $disksok/$disksno disks OK"
exit 0;
elif [[ ! -z "$result" && "$result" =~ "no raid" ]];then
echo "UNKNOWN: no fake RAID configured"
exit 3;
else
echo "CRITICAL: RAID Status is KO, with $disksok/$disksno disks OK"
exit 2;
fi
else
echo "UNKNOWN: no dmraid binary found - please install dmraid"
exit 3;
fi
elif [[ ! -z "$type" && "$type" =~ "hardware" ]];then
okraid=0;
oksmart=0;
koraid=0;
kosmart=0;
if [[ ! -z "$subtype" && "$subtype" =~ "--megaraid" ]];then
bin=`/usr/bin/which MegaCli64`
if [[ ! -z $bin ]];then
if [[ ! -z "$element" && "$element" =~ "--volume" ]];then
result=`$bin -LDinfo -Lall -aALL | grep State | awk '{print $3}'`
if [[ ! -z "$result" && $result =~ "Optimal" ]];then
echo "OK: RAID Volume state is $result"
exit 0;
else
echo "CRITICAL: RAID Volume state is $result"
exit 2;
fi
elif [[ ! -z "$element" && "$element" =~ "--physical" ]];then
diskno=`$bin -PDList -aALL | grep "S.M.A.R.T alert" | wc -l`
for (( d=1; d<=$diskno; d++ ))
do
result=`$bin -PDList -aALL | grep "Firmware state" | sed -n "$d p" | awk '{print $3}' | sed 's/,//g'`
if [[ ! -z "$result" && $result =~ "Online" ]];then
echo "RAID Status for Physical Disk number $d is OK"
((okraid++));
else
echo "RAID Status for Physical Disks number $d is KO"
((koraid++));
fi
done
for (( d=1; d<=$diskno; d++ ))
do
result=`$bin -PDList -aALL | grep "S.M.A.R.T alert" | sed -n "$d p" | awk '{print $8}'`
if [[ ! -z "$result" && $result =~ "No" ]];then
echo "S.M.A.R.T Status for Physical Disk number $d is OK"
((oksmart++));
else
echo "S.M.A.R.T. Status for Physical Disks number $d is KO"
((kosmart++));
fi
done
if [[ $koraid -eq 0 && $kosmart -eq 0 ]];then
echo "OK: RAID and S.M.A.R.T Status for all Physical Disks is OK"
exit 0;
elif [[ $koraid -eq 0 && $kosmart -ne 0 ]];then
echo "CRITICAL: S.M.A.R.T Status for some Physical Disks is KO"
exit 2;
elif [[ $koraid -ne 0 && "$kosmart" -eq 0 ]];then
echo "CRITICAL: RAID Status for some Physical Disks is KO"
exit 2;
elif [[ $koraid -ne 0 && $kosmart -ne 0 ]];then
echo "CRITICAL: RAID and S.M.A.R.T Status for some Physical Disks is KO"
exit 2;
fi
elif [[ ! -z "$element" && "$element" =~ "--battery" ]];then
result=`$bin -AdpBbuCmd -aAll | grep "Battery State" | awk '{print $3}'`
if [[ ! -z "$result" && $result =~ "OK" ]];then
echo "OK: RAID Controller Battery state is OK"
exit 0;
else
echo "CRITICAL: RAID Controller Battery state is $result"
exit 2;
fi
else
echo "UNKNOWN: please specify the element to check"
echo $usage;
exit 3;
fi
else
echo "UNKNOWN: No MegaCli64 binary found - please install MegaCli64"
exit 3;
fi
elif [[ ! -z "$subtype" && "$subtype" =~ "mpt" ]];then
modprobe mptctl
bin=`/usr/bin/which mpt-status`
bin2=`/usr/bin/which lspci`
bin3=`/usr/bin/which daemonize`
if [[ ! -z $bin ]];then
if [[ ! -z $bin2 ]];then
controller_status=`lspci | grep MPT`
if [[ ! -z $controller_status ]];then
if [[ ! -z $bin3 ]];then
controller=`$bin -p | grep id | awk '{print $3}' | sed 's/id=//g' | sed 's/,//g'`
if [[ ! -z $controller ]];then
result=`$bin -i $controller | grep OPTIMAL`
if [[ ! -z "$result" ]];then
echo "OK: RAID Status is OPTIMAL"
exit 0;
else
echo "CRITICAL: RAID Status is DEGRADED"
exit 2;
fi
else
echo "UNKNOWN: MPT Controller found but no RAID configured";
exit 3;
fi
else
echo "UNKNOWN: No daemonize binary found - please install daemonize";
exit 3;
fi
else
echo "UNKNOWN: Unable to find RAID Controller";
exit 3;
fi
else
echo "UNKNOWN: No lspci binary found - please install lspci";
exit 3;
fi
else
echo "UNKNOWN: No mpt-status binary found - please install mpt-status"
exit 3;
fi
else
echo "UNKNOWN: please specify the RAID Controller type"
echo $usage
exit 3;
fi
else
echo "UNKNOWN: please specify the RAID type"
echo $usage
exit 3;
fi
exit 0
Lo usage parla chiaro: il primo argomento identifica, per l’appunto, la tecnologia RAID utilizzata sul sistema target. Il secondo ed il terzo argomento, invece, dovranno essere specificati solo nel caso in cui si abbia a che fare con un RAID di tipo hardware. Nella fattispecie, essi rappresentano, rispettivamente, la tipologia di chipset utilizzata dal controller e l’oggetto di interesse della nostra query, ovvero il volume, i dischi fisici oppure la batteria (tale parametro ha senso solo se il chipset è di tipo LSI MegaRAID).
Configurazione di Nagios
Come al solito, il primo step consiste nel definire un comando che utilizzi lo script (in gergo plugin) riportato in precedenza:
# 'check_local_raid' command definition
define command{
command_name check_local_raid
command_line $USER1$/check_raid $ARG1$ $ARG2$ $ARG3$
}
tali direttive andranno opportunamente inserite all’interno del file /etc/nagios/objects/commands.cfg.
Successivamente si potrà procedere con la definizione del servizio che si occuperà del monitoraggio vero e proprio, da aggiungere alla configurazione dell’host target, in questo caso /etc/nagios/object/locahost.cfg:
define service{
use local-service ; Name of service template to use
host_name localhost
service_description RAID Status
check_command check_local_raid!--software
}
A questo punto non ci rimane che ricaricare la configurazione di Nagios per rendere effettive le suddette modifiche:
[root@linuxbox ~]# service nagios reload
ed abbiamo finito.
Alla prossima.