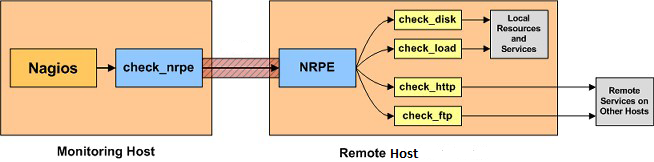
In questo post vi ho parlato di come configurare Nagios affinchè riesca a monitorare lo stato degli aggiornamenti relativi ad una macchina Windows Server 2008 R2.
Per qualche tempo tutto ha funzionato correttamente, fino a quando il servizio in questione ha cominciato a restituirmi dei timeout. Aver ridotto gli intervalli dei check non ha portato i risultati sperati, per cui ho dovuto armarmi di pazienza ed iniziare a fare un po’ di sano troubleshooting.
 Problema
Problema
Dopo l’uscita degli ultimi sistemi operativi di casa Microsoft (8, 10, Server 2012, Server 2012 R2), la verifica degli aggiornamenti relativi a Windows 7, Server 2008 e Server 2008 R2 (per i quali il supporto è ancora attivo) è diventato un processo lento e macchinoso, probabilmente a causa della minore priorità data agli OS in questione. Ecco la causa principale dei timeout di cui sopra. Come risolvere dunque? Procediamo utilizzando un metodo (quasi) infallibile, ovvero il divide et impera.
Step 1: verifica del timeout associato al comando check_nrpe
Il tool check_nrpe, utilizzato per interrogare lo stato della macchina Windows, prevede l’uso (facoltativo) della flag -t, utile per la definizione del tempo di timeout (che per default è pari a 10 secondi). Per questo motivo ho fatto in modo che il comando check_WMI_windows_updates prevedesse la possibilità di specificare un tempo di timeout libero a piacere (-t $ARG1$):
# nagios-WMI-windows-updates check command definition
define command {
command_name check_WMI_windows_updates
command_line /usr/lib64/nagios/plugins/check_nrpe -H $HOSTADDRESS$ -t $ARG1$ -c get_windows_updates
}
Nella fattispecie, il servizio che si avvale del suddetto comando ha un tempo di timeout pari a 600 secondi, come riportato di seguito:
define service{
use generic-service ; Name of service template to use
host_name Windows-Machine
service_description query WMI Updates for Microsoft Windows Machine
check_command check_WMI_windows_updates!600
normal_check_interval 120
}
Esso deve coincidere con il timeout del comando get_windows_updates definito all’interno del file \Pugins\V2\V2_nrpe_commands.cfg, il cui contenuto sarà:
command[get_windows_updates]=cscrip.exe //nologo //T:600 c:\nrpe\plugins\v2\check_windows_updates.wsf /w:0 /c:1
Il suddetto timeout va definito anche all’interno del file bin\nrpe.cfg, nel modo seguente:
command_timeout= 600
Tutte queste modifiche erano già state opportunamente trattate nell’ambito del mio post originale, ma ho ritenuto comunque utile rammentarle.
Step 2: verifica del timeout associato ai servizi di Nagios
Fortunatamente, l’NMS in questione ci consente di definire un tempo di timeout “globale” per i check dei servizi definiti dall’utente. Esso è presente all’interno del file /etc/nagios/nagios.cfg e la direttiva di nostro interesse è service_check_timeout da impostare come segue:
service_check_timeout=600
Riavviamo quindi Nagios per rendere effettive le modifiche appena apportate:
[root@linuxbox ~]# service nagios reload
Step 3: verifica dei timeout delle NAT translations
L’ultima fase di troubleshooting consiste nella verifica dei timeout associati alle NAT translations del router. Il dispositivo in questione è un Cisco 877 e per visualizzare le informazioni di nostro interesse occorre utilizzare il comando:
sh ip nat translations verbose
il cui output sarà simile al seguente:
extended, timing-out, use_count: 0, entry-id: 427758, lc_entries: 0 tcp 78.13.12.241:443 192.168.4.2:443 --- --- create 2w0d, use 00:00:51 timeout:300000, timing-out, flags:
Come si può notare, il timeout di default per le connessioni TCP è pari a 300000 ms (300 secondi ovvero 5 minuti), ergo dobbiamo incrementarlo fino a 600000 per allinearlo alla configurazione di Nagios. Per fare ciò è sufficiente lanciare il comando:
ip nat translation tcp-timeout 600
Salviamo la configurazione del router mediante un copy run start ed i timeout del servizio spariranno come per magia.
Il post termina qui, alla prossima.