Premessa
Prima di introdurre questa piccola guida, occorre spiegare cosa s’intende per WMI. Nella fattispecie, tale acronimo sta per Windows Management Instrumental, ovvero un’estensione del Win32 driver model, grazie alla quale è possibile monitorare e gestire le macchine (sia client che server) su cui è installato il sistema operativo di casa Microsoft (da Windows 2000 in poi).
Inulte dire che esistono già delle piattaforme sviluppate ad hoc che supportano le query WMI (tra cui SCOM), ma la cosa veramente interessante consiste nel poter sviluppare i propri sistemi di monitoraggio basati su scrip custom editati in VBscrip o PowerShell.
Ora, nel caso in cui si voglia allestire un sistema di monitoraggio che supporti le query WMI in ambiente open source, la scelta ricade necessariamente su nagios3. Inoltre, poichè nagios3 non supporta in modo nativo le query WMI, si rende indispensabile l’utilizzo di un tool che funge da tramite tra il server di monitoraggio e le macchine che verranno interrogate. Tale tool prende il nome di NRPE_NT (potete scaricarlo da qui, è gratuito).
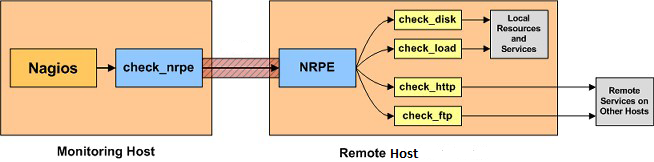
Come si può capire dall’immagine precedente, nagios3, attraverso il comando check_nrpe, invia una query ad NRPE_NT (installato su una macchina Windows), il quale la inoltrerà (comportandosi come un vero e proprio proxy) all’host Microsoft di destinazione.
Ricapitolando, abbiamo bisogno dei seguenti elementi per mettere in piedi il nostro sistema di monitoraggio WMI:
1) nagios3;
2) il plugin check_nrpe;
2) NRPE_NT;
3) i plugins V2 per NRPE_NT (potete scaricarli da qui).
Installazione di check_nrpe e configurazione di nagios3
Partendo dal presupposto che nagios3 sia già presente sulla nostra linux box, procediamo con l’installazione del plugin check_nrpe. Per fare ciò occorre digitare:
nightfly@nightbox:~$ sudo apt-get install nagios-nrpe-plugin
Adesso possiamo definire alcuni comandi custom da inviare alla macchina Windows su cui è installato NRPE_NT, affinchè quest’ultima possa inoltrare la query all’host di destinazione. In particolare, creiamo il file wmi.cfg all’interno della directory /etc/nagios-plugins/config, il cui contenuto sarà:
# nagios-WMI-cpu check command definition
define command {
command_name check_WMI_cpu
command_line /usr/lib/nagios/plugins/check_nrpe -H <IP macchina NRPE_NT> -c get_cpu -a $HOSTADDRESS$ $ARG1$ $ARG2$
}
# nagios-WMI-disk check command definition
define command {
command_name check_WMI_disk
command_line /usr/lib/nagios/plugins/check_nrpe -H<IP macchina NRPE_NT> -c get_disk -a $HOSTADDRESS$ $ARG1$ $ARG2$
}
# nagios-WMI-mem check command definition
define command {
command_name check_WMI_mem
command_line /usr/lib/nagios/plugins/check_nrpe -H<IP macchina NRPE_NT> -c get_mem -a $HOSTADDRESS$ $ARG1$ $ARG2$
}
Ovviamente esistono altri comandi di cui si può usufruire, una lista a cui far riferimento la trovate qui.
Bene, adesso definiamo i servizi da monitorare per i nostri host Windows. Un file di configurazione da utilizzare come template e da posizionare nella directory /etc/nagios3/conf.d è il seguente:
define host {
host_name hostWindows
alias nightflyclient
address 192.168.1.11
use generic-host
}
define service{
use generic-service ; Name of service template to use
host_name hostWindows
service_descripion query WMI CPU for Microsoft Windows Machine
check_command check_WMI_cpu!CPU0!80,90
}
define service{
use generic-service ; Name of service template to use
host_name hostWindows
service_descripion query WMI Disk for Microsoft Windows Machine
check_command check_WMI_disk!C:!80,90
}
define service{
use generic-service ; Name of service template to use
host_name hostWindows
service_descripion query WMI Memory for Microsoft Windows Machine
check_command check_WMI_mem!_TOTAL!80,90
}
Salviamo il file appena creato e passiamo all’installazione di NRPE_NT sulla macchina Windows che fungerà da proxy per le query WMI.
Installazione di NRPE_NT
Per prima cosa scompattiamo il file nrpe_nt.0.8b-bin.rar e salviamone il contenuto all’interno della directory NRPE_NT presente in C:
Creiamo inoltre, sempre all’interno della directory NRPE_NT, la cartella Plugins ed all’interno di quest’ultima creiamo un’ulteriore cartella che chiameremo V2, nella quale salveremo il contenuto del file wmi-1.3.rar.
A questo punto editiamo il file nrpe.cfg presente nella directory bin, che si trova dentro la cartella NRPE_NT.
I punti da modificare sono sostanzialmente tre, ovvero:
allowed_hosts=<IP della linux box su cui è installato nagios3>
(in modo da consentire a nagios di connettersi ad NRPE_NT per usarlo come proxy);
dont_blame_nrpe=1
(in modo da consentire l’esecuzione di comandi da remoto);
include=C:\NRPE_NT\Plugins\V2\V2_nrpe_commands.cfg
(per dare in pasto ad NRPE_NT alcuni comandi aggiuntivi di monitoraggio).
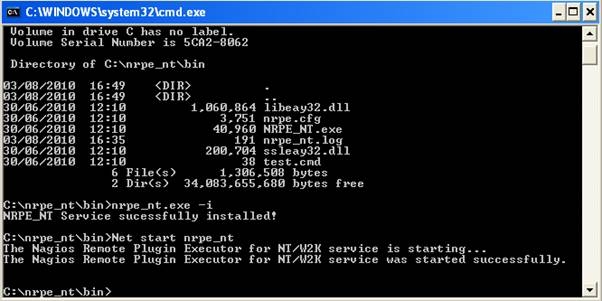
Una volta configurato NRPE_NT passiamo alla sua installazione. Per fare ciò apriamo il prompt (start->esegui->cmd), posizioniamoci in C: e successivamente nella dir bin presente in NRPE_NT.
A questo punto lanciamo il comando:
nrpe_nt.exe -i
dove la flag -i sta per install.
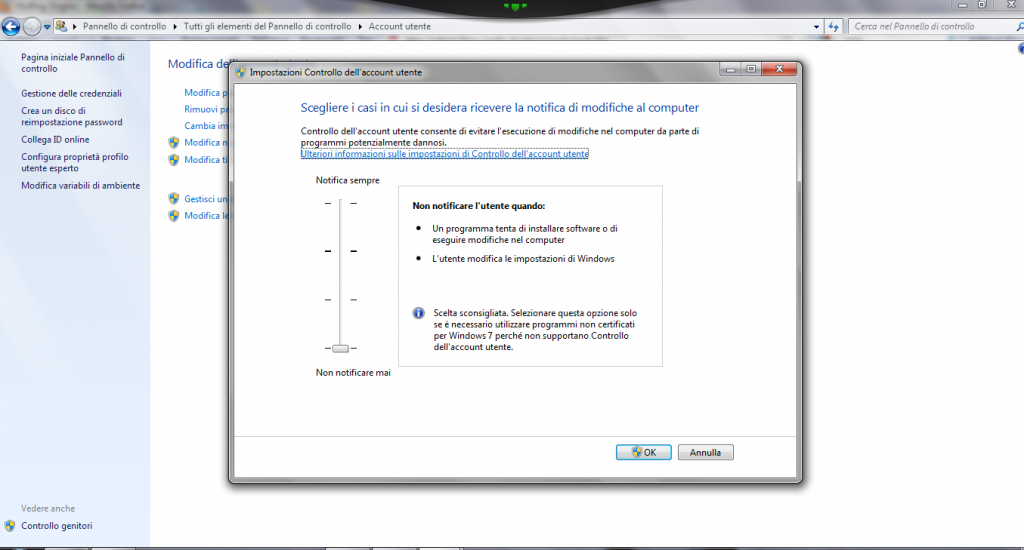
NB: nel caso in cui stiate utilizzando una macchina su cui è installato Windows 7, prima di procedere con l’installazione di NRPE_NT dovete modificare le impostazioni di controllo dell’account utente:
Una volta installato il servizio NRPE_NT occorre avviarlo mediante il comando net start nrpe_nt oppure attraverso pannello di controllo -> strumenti di amministrazione -> servizi.
Controlliamo ora che NRPE_NT sia in ascolto sulla nostra macchina digitando:
netstat -ano | find ":5666"
il cui output dovrà essere simile al seguente:
TCP 0.0.0.0:5666 0.0.0.0:0 LISTENING 1976
NB: affinchè la macchina su cui è installato nagios3 possa connettersi ad NRPE_NT occorre disabilitare il Firewall di Windows.
Test per verificare il corretto funzionamento di NRPE_NT
Per verificare il corretto funzionamento di NRPE_NT effettuiamo il login sulla nostra linux box e posizioniamoci nella directory /usr/lib/nagios/plugins. A questo punto lanciamo il comando:
nightfly@nightbox:/usr/lib/nagios/plugins$ ./check_nrpe -H <IP della macchina Windows su cui è installato NRPE_NT>
Se l’output immediatamente successivo sarà:
NRPE_NT v0.8b/2.0
vuol dire che NRPE_NT funziona correttamente.
Infine, riavviamo nagios3 per rendere effettive le modifiche della sua configurazione messe in atto nella prima parte di questa guida:
nightfly@nightbox:~$ sudo service nagios3 restart
Adesso sarà possibile monitorare gli host Windows mediante nagios3 ed NRPE_NT.
See ya.