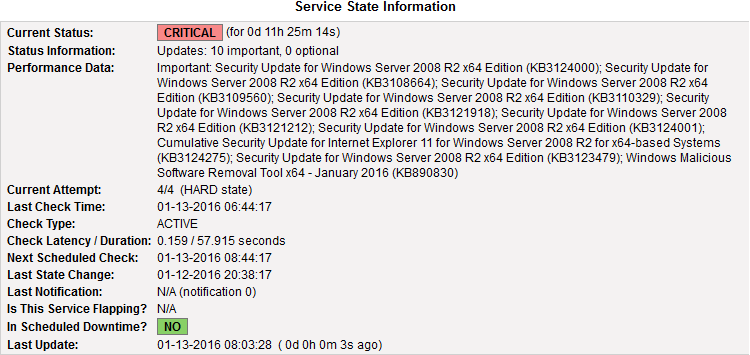
A quanti di voi sarà capitato di dover fare i conti con un certificato X.509 scaduto (magari installato su un server in produzione) che avete scordato (per un motivo o per un altro) di rinnovare?
Ebbene, tramite il seguente scrip bash (da integrare a Nagios) non dovremo più “appuntarci” la data di scadenza dei suddetti certificati, poichè sarà proprio l’NMS a ricordarci (a tempo debito) di procedere con il rinnovo.
 Ecco lo scrip:
Ecco lo scrip:
#!/bin/bash
############Scrip powered by nightfly. Default values for warn and crit############
############(if not defined by command line) are 10 and 3 respectivley##############
host=$1
port=$2
warn=$3
crit=$4
function get_cert_datetime() {
date=`echo | openssl s_client -connect $host:$port 2>/dev/null | openssl x509 -noout -dates | grep notAfter | awk -F "=" '{print $2 }'`
day=`echo $date | awk '{print $2}'`
case $day in
1)
day=01;
;;
2)
day=02;
;;
3)
day=03;
;;
4)
day=04;
;;
5)
day=05;
;;
6)
day=06;
;;
7)
day=07;
;;
8)
day=08;
;;
9)
day=09;
;;
esac
month=`echo $date | awk '{print $1}'`
case $month in
Jan)
month=01;
;;
Feb)
month=02;
;;
Mar)
month=03;
;;
Apr)
month=04;
;;
May)
month=05;
;;
Jun)
month=06;
;;
Jul)
month=07;
;;
Aug)
month=08;
;;
Sep)
month=09;
;;
Oct)
month=10;
;;
Nov)
month=11;
;;
Dec)
month=12;
;;
esac
year=`echo $date | awk '{print $4}'`
time=`echo $date | awk '{print $3}'`
hours=`echo $time | awk -F ":" '{print $1}'`
minutes=`echo $time | awk -F ":" '{print $2}'`
seconds=`echo $time | awk -F ":" '{print $3}'`
datecheck="$year$month$day"
datecheckepoch=`date -d "$datecheck" +"%s"`
datenow=`date +"%Y%m%d"`
datenowepoch=`date -d "$datenow" +"%s"`
}
get_cert_datetime;
get_time_diff() {
#time difference in hours, minutes and seconds
hoursnow=`date +"%H"`
minutesnow=`date +"%M"`
secondsnow=`date +"%S"`
hourstoseconds=`expr $hoursnow "*" 3600`
minutestosecond=`expr $minutesnow "*" 60`
secondsnowtot=`expr $hourstoseconds + $minutestosecond + $secondsnow`
hourschecktoseconds=`expr $hours "*" 3600`
minuteschecktoseconds=`expr $minutes "*" 60`
secondschecktot=`expr $hourschecktoseconds + $minuteschecktoseconds + $seconds`
secondsdiff=`expr $secondschecktot - $secondsnowtot`
secondstoexpire=`expr 86400 - $secondsnowtot + $secondschecktot`
minutestoexpire=`expr $secondstoexpire / 60`
spareseconds=`expr $secondstoexpire % 60`
hourstoexpire=`expr $minutestoexpire / 60`
spareminutes=`expr $minutestoexpire % 60`
}
get_time_diff;
timestamp_to_days() {
#unix timestamp to days conversion
secondsleft=`expr $datecheckepoch - $datenowepoch`
minutesleft=`expr $secondsleft / 60`
hoursleft=`expr $minutesleft / 60`
daysleft=`expr $hoursleft / 24`
}
timestamp_to_days;
if [[ ! -z $host && ! -z $port ]];then
if [[ $datecheckepoch -gt $datenowepoch ]];then
if [[ -z $warn && -z $crit ]];then
if [[ $daysleft -ge 10 ]];then
echo "OK: the X.509 certificate will expire in $daysleft days $hourstoexpire hours $spareminutes minutes $spareseconds seconds | days_left=$daysleft"
exit 0
elif [[ $daysleft -lt 10 && $daysleft -gt 3 ]];then
echo "WARNING: the X.509 certificate will expire in $daysleft days $hourstoexpire hours $spareminutes minutes $spareseconds seconds | days_left=$daysleft"
exit 1
elif [[ $daysleft -lt 3 && $daysleft -gt 0 ]];then
echo "CRITICAL: the X.509 certificate will expire in $daysleft days $hourstoexpire hours $spareminutes minutes $spareseconds seconds | days_left=$daysleft"
exit 2
elif [[ $daysleft -eq 0 && $secondsdiff -gt 0 ]];then
echo "CRITICAL: the X.509 certificate will expire in $hourstoexpire hours $spareminutes minutes $spareseconds seconds"
exit 2
fi
elif [[ ! -z $warn && ! -z $crit ]];then
if [[ $warn -gt $crit ]];then
if [[ $daysleft -ge $warn ]];then
echo "OK: the X.509 certificate will expire in $daysleft days $hourstoexpire hours $spareminutes minutes $spareseconds seconds | days_left=$daysleft"
exit 0
elif [[ $daysleft -lt $warn && $daysleft -gt $crit ]];then
echo "WARNING: the X.509 certificate will expire in $daysleft days $hourstoexpire hours $spareminutes minutes $spareseconds seconds | days_left=$daysleft"
exit 1
elif [[ $daysleft -lt $crit && $daysleft -gt 0 ]];then
echo "CRITICAL: the X.509 certificate will expire in $daysleft days $hourstoexpire hours $spareminutes minutes $spareseconds seconds | days_left=$daysleft"
exit 2
elif [[ $daysleft -eq 0 && $secondsdiff -gt 0 ]];then
echo "CRITICAL: the X.509 certificate will expire in $hourstoexpire hours $spareminute minutes $spareseconds seconds | days_left=$daysleft"
exit 2
fi
fi
else
echo "Usage: check_ssl_cert_exp <host> <port> [<warn left days> <crit left days>]"
echo "Warn threshold has to be greater then the Crit one"
exit 3
fi
else
echo "Usage: check_ssl_cert_exp <host> <port> [<warn left days> <crit left days>]"
echo "Both thresholds have to be used"
exit 3
fi
else
echo "CRITICAL: the X.509 certificate is expired"
exit 2
fi
else
echo "Usage: check_ssl_cert_exp <host> <port> [<warn left days> <crit left days>]"
echo "Please set the hostname and the port at least"
exit 3
fi
Ho deciso di adoperare le funzioni in modo da suddividere logicamente le varie operazioni che vengono effettuate per il calcolo del tempo che intercorre alla data di scadenza del certificato.
I parametri da utilizzare sono 4 in tutto, di cui 2 mandatori (hostname/FQDN e porta) e 2 facoltativi (soglia di WARNING e soglia di CRITICAL).
Per prima cosa (tramite la funzione get_cert_datetime()) individuo la data di scadenza riportata sul certificato (campo notAfter), utilizzando l’applicativo s_client della suite openssl. Successivamente effettuo un parsing dell’output, ricavando giorno, mese, anno, ora, minuto e secondo di scadenza, convertendo quindi tali informazioni in Unix epoch.
Successivamente, mediante la funzione get_time_diff(), calcolo la differenza (in termini di ore, minuti e secondi), tra l’ora attuale e quella di scadenza del certificato. Inoltre, utilizzando la variabile secondsdiff, nel caso in cui mi dovessi trovare proprio nel giorno di scadenza, riesco a capire se il certificato sta per scadere oppure è già scaduto.
A questo punto procedo con tutta una serie di confronti tra variabili e nella fattispecie verifico che la data attuale sia anteriore a quella di scadenza:
if [[ $datecheckepoch -gt $datenowepoch ]];then
Se è effettivamente questo il caso, controllo, rispettivamente, che le soglie di WARNING e di CRITICAL siano state definite e che siano logicamente coerenti (con WARNING > CRITICAL):
elif [[ ! -z $warn && ! -z $crit ]];then
if [[ $warn -gt $crit ]];then
Dopodichè faccio un confronto tra il giorno attuale e quello di scadenza, tenendo in considerazione le suddette soglie oppure i valori di default (10 e 3 nel caso in cui esse non siano state definite esplicitamente). Se mi trovo proprio nel giorno di scadenza verifico che la variabile secondsdiff sia un intero strettamente positivo, restituendo un errore di tipo CRITICAL ed il tempo mancante alla scadenza.
Ovviamente, anche nel caso in cui la data attuale sia successiva a quella di scadenza verrà restituito un errore di tipo CRITICAL segnalando che il certificato è già scaduto.
Configurazione di Nagios
Per prima cosa occorre definire il comando che fa uso del suddetto scrip (check_ssl_cert_exp), ovvero:
# 'check_ssl_exp' command definition
define command{
command_name check_ssl_exp
command_line $USER1$/check_ssl_cert_exp $HOSTADDRESS$ $ARG1$ $ARG2$ $ARG3$
}
Successivamente possiamo creare il servizio che si occuperà di controllare la scadenza del certificato X.509:
define service{
use local-service ; Name of service template to use
host_name localhost
service_descripion SSL Certificate Expiration Date
check_command check_ssl_exp!443!10!3
notifications_enabled 0
}
Infine riavviamo Nagios per rendere effettive le suddette modifiche:
[root@NMS ~]# service nagios reload
E’ tutto. Alla prossima.