Qualche giorno fa Nagios mi ha segnalato un allarme di sicurezza che mi ha lasciato alquato basito:
When a syslog message is generated by the device a SEC info IPACCESSLOGP list 102 denied tcp 77.223.136.170(0) - 95.245.162.62(0), 1 packet 9:5:46:40.62
In soldoni, l’ACL attiva sull’interfaccia dialer (WAN) del mio router ha “scartato” un segmento TCP proveniente dall’IP 77.223.136.170 (porta 0) e diretto al mio (vecchio) IP pubblico (ovvero 95.245.162.62, porta 0).
Ora, è sufficiente avere un minimo di dimestichezza con lo stack TCP/IP per capire che l’anomalia sta proprio nella porta sorgente ed in quella di destinazione. Infatti, la porta 0 è riservata ed il suo impiego può avvenire per i motivi (leciti) più disparati.
Ad esempio, nel caso in cui il pacchetto IP (formato da header + payload) superi la MTU del link che deve attraversare, esso subirà un processo specifico, denominato “frammentazione”.
In particolare, essendo l’header TCP parte del payload IP (per via dell’incapsulamento – vedi immagine sottostante), ciascun frammento potrebbe contenere la suddetta intestazione per intero o solo parzialmente. Nel primo caso, l’header TCP originario si troverebbe soltanto nel primo frammento, mentre tutti gli altri conterrebbero la sola intestazione IP (dotata di ID specifico del frammento, offset per la ricostruzione del traffico in fase di ricezione – dimensione e bit MF – More Fragment – pari a 0 o 1 a seconda che si tratti dell’ultimo frammento o meno).
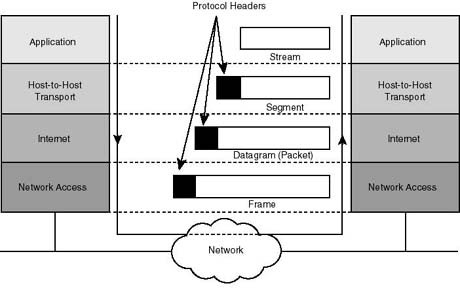
Più in generale, la porta TCP/UDP pari a 0 potrebbe stare a significare, molto semplicemente, assenza di layer 4 (basti pensare al protocollo ICMP).
Per quanto riguarda, invece, l’uso malevolo della porta 0, possiamo distinguere 3 macro-tipologie di casi:
1) Attacchi di tipo fingerprint. Essi si basano sul presupposto che spesso e volentieri le ACL non possono essere definite in modo tale da droppare esplicitamente il traffico in ingresso sulla porta 0 (TCP o UDP), ergo puntare ad essa è un modo abbastanza efficace (ma non infallibile) per ottenere info sulla tipologia di router oggetto di interesse (OS fingerprint – leggete questo per ulteriori dettagli);
2) Attacchi volti ad “aggirare” le ACL. Ad esempio, forzando la frammentazione del pacchetto IP ed agendo sul campo offset, si potrebbe riuscire, in teoria, a sovrascrivere parte dell’intestazione TCP originaria (che punta ad una porta di destinazione “lecitamente” raggiungibile dall’esterno, come potrebbe essere la 25 per il protocollo SMTP) con una porta non accessibile dall’esterno (ad esempio la 23 per il protocollo Telnet). Per ulteriori dettagli su tale tipologia di attacco (denominato tiny overlapping fragment attack) leggete questo.
3) Attacchi di tipo DoS/DDoS. Forzando la frammentazione dei pacchetti IP sottostanti al layer 4 (TCP/UDP) si potrebbe riuscire a “sovraccaricare” il router di destinazione, soprattutto per via dell’overhead dovuto all’attività di “ricostruzione” del traffico. Inoltre, puntando ad una porta non lecita, ad esempio la 0, lo si costringerebbe ad inviare dei messaggi ICMP Port Unreachable (se abilitati sull’interfaccia), sovraccaricandolo ulteriormente.
Della casistica appena illustrata credo che l’allarme ricada, molto banalmente, negli attacchi di tipo fingerprint. Ovviamente ho alzato il livello di attenzione per evitare “brutte” sorprese in futuro.
Vi terrò comunque aggiornati.
Aggiornamento 1
A quanto pare si è trattato proprio di un portscan/fingerprint. Infatti, dopo circa 5 giorni dallo scan sulla porta TCP 0, ho registrato il seguente traffico:
Jan 25 15:29:15 192.168.2.1 1738: 001735: Jan 25 15:29:14.483 UTC: %SEC-6-IPACCESSLOGP: list 101 permitted tcp 77.223.136.170(443) -> 79.31.118.x(43616), 1 packet Jan 25 15:29:17 192.168.2.1 1739: 001736: Jan 25 15:29:15.988 UTC: %SEC-6-IPACCESSLOGP: list 101 denied tcp 77.223.136.170(256) -> 79.31.118.x(43617), 1 packet Jan 25 15:29:18 192.168.2.1 1740: 001737: Jan 25 15:29:17.200 UTC: %SEC-6-IPACCESSLOGP: list 101 denied tcp 77.223.136.170(111) -> 79.31.118.x(43617), 1 packet Jan 25 15:29:19 192.168.2.1 1741: 001738: Jan 25 15:29:18.204 UTC: %SEC-6-IPACCESSLOGP: list 101 permitted tcp 77.223.136.170(1106) -> 79.31.118.x(43616), 1 packet Jan 25 15:29:20 192.168.2.1 1742: 001739: Jan 25 15:29:19.204 UTC: %SEC-6-IPACCESSLOGP: list 101 denied tcp 77.223.136.170(700) -> 79.31.118.x(43617), 1 packet Jan 25 15:29:20 192.168.2.1 1743: 001740: Jan 25 15:29:20.208 UTC: %SEC-6-IPACCESSLOGP: list 101 permitted tcp 77.223.136.170(3493) -> 79.31.118.x(43616), 1 packet Jan 25 15:29:22 192.168.2.1 1744: 001741: Jan 25 15:29:21.213 UTC: %SEC-6-IPACCESSLOGP: list 101 denied tcp 77.223.136.170(726) -> 79.31.118.x(43617), 1 packet Jan 25 15:29:24 192.168.2.1 1746: 001743: Jan 25 15:29:23.365 UTC: %SEC-6-IPACCESSLOGP: list 101 denied tcp 77.223.136.170(777) -> 79.31.118.x(43618), 1 packet Jan 25 15:29:26 192.168.2.1 1747: 001744: Jan 25 15:29:25.046 UTC: %SEC-6-IPACCESSLOGP: list 101 denied tcp 77.223.136.170(111) -> 79.31.118.x(43618), 1 packet
Aggiornamento 2
In data 26 Gennaio ho ricevuto un altro pacchetto da/verso la suddetta porta:
When a syslog message is generated by the device a SEC info IPACCESSLOGP list 101 denied tcp 23.236.147.202(0) - 79.31.118.x(0), 1 packet 0:14:52:02.45
Vediamo se tra qualche giorno il nuovo IP sorgente utilizzerà lo stesso ordine di port probing del suo predecessore.
Aggiornamento 3
Come volevasi dimostrare, a distanza di qualche ora è arrivato il port probing vero e proprio:
Jan 27 18:36:33 192.168.2.1 19380: 019433: Jan 27 18:36:32.479 UTC: %SEC-6-IPACCESSLOGP: list 101 denied tcp 23.236.147.202(139) -> 79.31.118.x(46096), 1 packet Jan 27 18:36:35 192.168.2.1 19381: 019434: Jan 27 18:36:34.475 UTC: %SEC-6-IPACCESSLOGP: list 101 denied tcp 23.236.147.202(1002) -> 79.31.118.x(46097), 1 packet Jan 27 18:36:36 192.168.2.1 19382: 019435: Jan 27 18:36:35.500 UTC: %SEC-6-IPACCESSLOGP: list 101 permitted tcp 23.236.147.202(2701) -> 79.31.118.x(46095), 1 packet Jan 27 18:36:36 192.168.2.1 19383: 019436: Jan 27 18:36:36.500 UTC: %SEC-6-IPACCESSLOGP: list 101 permitted tcp 23.236.147.202(11967) -> 79.31.118.x(46095), 1 packet Jan 27 18:36:38 192.168.2.1 19384: 019437: Jan 27 18:36:37.552 UTC: %SEC-6-IPACCESSLOGP: list 101 permitted tcp 23.236.147.202(1494) -> 79.31.118.x(46095), 1 packet Jan 27 18:36:39 192.168.2.1 19385: 019438: Jan 27 18:36:38.556 UTC: %SEC-6-IPACCESSLOGP: list 101 permitted tcp 23.236.147.202(8021) -> 79.31.118.x(46095), 1 packet Jan 27 18:36:43 192.168.2.1 19387: 019440: Jan 27 18:36:42.353 UTC: %SEC-6-IPACCESSLOGP: list 101 denied tcp 23.236.147.202(139) -> 79.31.118.x(46097), 1 packet Jan 27 18:36:48 192.168.2.1 19388: 019441: Jan 27 18:36:47.154 UTC: %SEC-6-IPACCESSLOGP: list 101 denied tcp 23.236.147.202(139) -> 79.31.118.x(46095), 1 packet
Anche in questo caso le porte oggetto dell’attacco sono quelle > 1023. Ho quindi fatto qualche modifica all’ACL configurata sulla dia0 del mio router, sostituendo la regola:
access-list 101 permit tcp any gt 1023 any log
con:
access-list 101 permit tcp any gt 1023 any established log
in modo tale da consentire il traffico proveniente dalle porte > 1023 solo se si riferiscono a delle connessioni già esistenti.
Aggiornamento 4
Sono riuscito a ricreare parzialmente la suddetta tipologia di traffico, utilizzando un apposito tool denominato hping, il quale è in grado di forgiare dei pacchetti RAW/TCP/UDP/ICMP da impiegare durante le operazioni di OS fingerprint e non solo.
Ad esempio, mediante il comando:
[root@linuxbox ~]# hping3 -S -V <mio indirizzo IP>
sono riuscito a generare una sfilza di pacchetti TCP recanti i classici 40 byte di header, payload 0 e flag SYN settata a 1, la cui destinazione proprio è la famigerata porta 0.
Di seguito riporto il tracciato tcpdump da locale (grazie al quale si può notare che la porta sorgente è una porta alta, ovvero maggiore di 1023, e che la porta di destinazione è sempre la 0):
09:41:14.967184 IP 192.168.1.1.1232 > 79.31.118.x.0: Flags [S], seq 2094000106, win 512, length 0 09:41:15.967305 IP 192.168.1.1.1233 > 79.31.118.x.0: Flags [S], seq 517260399, win 512, length 0 09:41:16.967425 IP 192.168.1.1.1234 > 79.31.118.x.0: Flags [S], seq 399923675, win 512, length 0 09:41:17.967477 IP 192.168.1.1.1235 > 79.31.118.x.0: Flags [S], seq 725026004, win 512, length 0 09:41:18.967573 IP 192.168.1.1.rmtcfg > 79.31.118.x.0: Flags [S], seq 1830159741, win 512, length 0 09:41:19.967638 IP 192.168.1.1.1237 > 79.31.118.x.0: Flags [S], seq 342672970, win 512, length 0
Mentre il log generato dal mio router è il seguente:
Apr 3 09:39:35 192.168.2.1 108805: 108943: Apr 3 08:39:34.979 UTC: %SEC-6-IPACCESSLOGP: list 101 denied tcp 95.254.89.x(1232) -> 79.31.118.x(0), 1 packet Apr 3 09:39:37 192.168.2.1 108807: 108945: Apr 3 08:39:36.979 UTC: %SEC-6-IPACCESSLOGP: list 101 denied tcp 95.254.89.x(1233) -> 79.31.118.x(0), 1 packet Apr 3 09:39:39 192.168.2.1 108808: 108946: Apr 3 08:39:38.980 UTC: %SEC-6-IPACCESSLOGP: list 101 denied tcp 95.254.89.x(1234) -> 79.31.118.x(0), 1 packet Apr 3 09:39:41 192.168.2.1 108809: 108947: Apr 3 08:39:40.980 UTC: %SEC-6-IPACCESSLOGP: list 101 denied tcp 95.254.89.x(1235) -> 79.31.118.x(0), 1 packet Apr 3 09:39:43 192.168.2.1 108810: 108948: Apr 3 08:39:42.981 UTC: %SEC-6-IPACCESSLOGP: list 101 denied tcp 95.254.89.x(1236) -> 79.31.118.x(0), 1 packet Apr 3 09:39:45 192.168.2.1 108811: 108949: Apr 3 08:39:44.977 UTC: %SEC-6-IPACCESSLOGP: list 101 denied tcp 95.254.89.x(1237) -> 79.31.118.x(0), 1 packet
Invece, forzando a 0 la porta sorgente del suddetto traffico (e mantenendola tale per tutta la durata del test – opzione -k) attraverso il comando:
[root@linuxbox ~]# hping3 -S -VV -s 0 -k <mio indirizzo IP>
sono riuscito ad intercettarlo localmente come dimostrato dal seguente tracciato:
10:32:21.495218 IP 192.168.1.1.0 > 79.31.118.x.0: Flags [S], seq 1600061111, win 512, length 0 10:32:22.495334 IP 192.168.1.1.0 > 79.31.118.x.0: Flags [S], seq 965785080, win 512, length 0 10:32:23.495411 IP 192.168.1.1.0 > 79.31.118.x.0: Flags [S], seq 677172521, win 512, length 0 10:32:24.495492 IP 192.168.1.1.0 > 79.31.118.x.0: Flags [S], seq 473418678, win 512, length 0
ma è stato successivamente scartato dal router sorgente, ergo non è mai giunto a destinazione.
Nei prossimi giorni proverò a ripetere il test utilizzando il router di un vendor differente.