Un po’ di teoria (ToS vs DiffServ)
Il QoS (acronimo che sta ad indicare il cosiddetto Quality of Service) è una tecnica L3 per la prioritizzazione del traffico, in grado cioè di garantire una banda minima e/o bassi livelli di latenza e jitter (a seconda dei casi e delle esigenze). Tutte le politiche di QoS si basano su un campo dell’header IP, denominato DS filed (un tempo ToS – Type of Service – ormai deprecato). In particolare, esso presenta la seguente struttura:
DS5 DS4 DS3 DS2 DS1 DS0 ECN ECN
dove i 3 bit più significativi (DS5, DS4 e DS3) rappresentano, per il ToS, alla cosiddetta IP Precedence. Ad esempio, il pattern DiffServ 101 000 indica una priorità pari a 5 (ovvero la traduzione del digit 101 in decimale). Da ciò si evince che tutte le politiche QoS basate su DiffServ che tengono conto dei soli 3 bit più significativi, sono perfettamente retrocompatibili con il ToS (e quindi con tutti i dispositivi più datati che supportano esclusivamente tale tipologia di QoS).
NB: I 6 bit DS prendono il nome di DSCP (Differentiated Services Code Point).
Il motivo per cui il protocollo DiffServ è riuscito a soppiantare quasi completamente il ToS è molto semplice: la sua maggiore granularità nella gestione del traffico interessante (ovvero quello oggetto delle politiche di QoS) rispetto al suo predecessore.
Ancora teoria (DiffServ PHB)
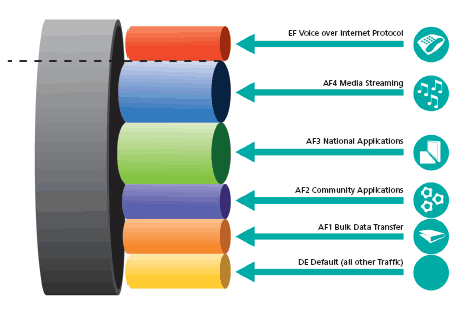 Il DiffServ prevede 5 tipologie di comportamento (PHB – Per Hop Behaviour) che i router attraversati da uno specifico datagramma possono intraprendere. Essi sono i seguenti:
Il DiffServ prevede 5 tipologie di comportamento (PHB – Per Hop Behaviour) che i router attraversati da uno specifico datagramma possono intraprendere. Essi sono i seguenti:
1) Default PHB, con i bit DS settati a 000 000 – Best Effort (aka nessuna garanzia di instradamento);
2) Expedited Forwarding (EF PHB), con i bit DS settati a 101110 – il migliore in assoluto (poichè molto affidabile, prevede bassissimi tempi di latenza e valori di jitter minimi, nonchè basse probabilità che il datagramma venga droppato);
3) Assured Forwarding (AF PHB), che fa fede alla seguente tabella:
Low Drop AF11 (DSCP 10) AF21 (DSCP 18) AF31 (DSCP 26) AF41 (DSCP 34)
Med Drop AF12 (DSCP 12) AF22 (DSCP 20) AF32 (DSCP 28) AF42 (DSCP 36)
High Drop AF13 (DSCP 14) AF23 (DSCP 22) AF33 (DSCP 30) AF43 (DSCP 38)
4) Voice Admit PHB, con i bit DS settati a 101100 – identico all’EF PHB per affidabilità e bassa latenza, si basa sul CAC (Call Admission Control);
5) Class Selector (CS PHB): retrocompatibile con l’IP Precedence del ToS, fa fede alla seguente tabella:
DSCP Binary Decimal Typical Application Examples
CS0 000 000 0 N/A N/A (best effort)
CS1 001 000 8 Scavenger YouTube, Gaming, P2P
CS2 010 000 16 OAM SNMP,SSH,Syslog
CS3 011 000 24 Signaling SCCP,SIP,H.323
CS4 100 000 32 Realtime TelePresence
CS5 101 000 40 Broadcast video Cisco IPVS
CS6 110 000 48 Network Control EIGRP,OSPF,HSRP,IKE
In definitiva, è possibile utilizzare la seguente tabella per la mappatura dei pattern DSCP con l’IP Precedence:
Value Decimal Meaning Drop Probability Equivalent IP Precedence Value
101 110 46 EF N/A 101 Critical
000 000 0 Best Effort N/A 000 - Routine
001 010 10 AF11 Low 001 - Priority
001 100 12 AF12 Medium 001 - Priority
001 110 14 AF13 High 001 - Priority
010 010 18 AF21 Low 010 - Immediate
010 100 20 AF22 Medium 010 - Immediate
010 110 22 AF23 High 010 - Immediate
011 010 26 AF31 Low 011 - Flash
011 100 28 AF32 Medium 011 - Flash
011 110 30 AF33 High 011 - Flash
100 010 34 AF41 Low 100 - Flash Override
100 100 36 AF42 Medium 100 - Flash Override
100 110 38 AF43 High 100 - Flash Override
Definizione delle politiche di QoS sul router Cisco 877
Dopo questa breve carrellata teorica veniamo alla pratica. Per prima cosa occorre distinguere tra le politiche di QoS in ingresso e quelle in uscita.
Le prime si basano sul cosiddetto CAR (Committed Access Rate); per le seconde, invece, bisogna utilizzare l’accoppiata class-map/policy-map. In entrambi i casi occorre definire un’opportuna ACL per l’identificazione del traffico interessante, ad esempio:
access-list 105 remark inbound VOIP (SIP/RTP) traffic gets top priority (5) with CAR
access-list 105 permit udp any any eq 5060
access-list 105 permit udp any any range 10000 20000
Alla luce di quanto detto, per il QoS del traffico in ingresso possiamo utilizzare la seguente configurazione:
rate-limit input access-group 105 128000 65536 65536 conform-action set-prec-transmit 5 exceed-action set-prec-continue 0
rate-limit input 13414000 13000000 13400000 conform-action transmit exceed-action drop
Per il traffico in uscita, invece, dobbiamo digitare:
class-map voice
match access-group 105
policy-map policy1
class voice
priority 128
class class-default
bandwidth 795
fair-queue
Per prima cosa abbiamo definito la class-map voice che fa uso dell’ACL precedentemente definita. La suddetta class-map andrà a popolare la policy-map policy1 (che può essere vista come una sorta di contenitore di una o più class-map), dentro la quale definiremo il traffico prioritario (grazie alla direttiva priority). Il valore si intende espresso in kbps.
La class-default, invece, consente di riservare la banda minima garantita per tutto il traffico che non rientra nel QoS, dove fair-queue è sinonimo di best effort. Anche in questo caso parliamo di kbps. Ovviamente i valori assegnati sono stati calcolati basandosi sull’uplink rate dell’interfaccia ADSL del router.
NB: per traffico prioritario si intende quello con bassa probabilità di drop e bassi valori di latenza/jitter.
L’ultimo step consiste nell’assegnazione della policy-map policy1 all’interfaccia fa0 (LAN) ed ATM0 (WAN). Per la LAN avremo:
interface FastEthernet0
no ip address
service-policy output policy1
mentre per la WAN:
interface ATM0
no ip address
no atm ilmi-keepalive
pvc 8/35
vbr-nrt 923 923 1
tx-ring-limit 3
service-policy out policy1
pppoe-client dial-pool-number 1
!
In particolare, la policy-map va assegnata direttamente al PVC ATM (e non all’interfaccia dialer come ci si potrebbe aspettare), previa definizione delle direttive vbr-nrt e tx-ring-limit.
La prima è indispensabile per la politica di controllo del traffico (detta GTS – Generic Traffic Shaping) supportata da questo tipo di interfaccia, dove il termine vbr-nrt sta per variable bit rate not real time (GTS ed ubr, ovvero l’undefined bit rate impostato di default sul PVC, non sono tra loro compatibili). La sintassi da utilizzare è la seguente:
vbr-nrt <Peak Cell Rate> <Sustained Cell Rate> <Maximum Burst Size>
Inoltre, per individuare i valori di PCR ed SCR ho applicato la seguente prassi:
1) ho identificato l’uplink rate della linea ADSL, utilizzando il comando:
sh atm int atm0
il cui output è simile al seguente:
VCIs per VPI: 1024,
Max. Datagram Size: 4528
PLIM Type: ADSL - 972Kbps Upstream, DMT, TX clocking: LINE
2) ho calcolato il 95% dell’ upstream rate, ed il valore risultante è servito a popolare sia PCR che SCR;
3) ho impostato l’MBR a 1.
La seconda direttiva (ovvero tx-ring-limit), serve, invece, per la gestione della coda (a livello HW) dell’interfaccia ATM. Nella fattispecie, limitando il buffer a soli 3 pacchetti, si fa in modo che la politica QoS possa essere applicata ai dati prima del loro ingresso nel buffer (dove il QoS non può più essere attuato).
Per ciò che concerne la visualizzazione delle statistiche relative al QoS (ad esempio il drop rate), è sufficiente utilizzare il comando show policy map, specificando l’interfaccia oggetto di analisi:
#sh policy-map interface atm0
il cui output sarà simile al seguente:
ATM0: VC 8/35 -
Service-policy output: policy1
queue stats for all priority classes:
queue limit 64 packets
(queue depth/total drops/no-buffer drops) 0/0/0
(pkts output/bytes output) 5590/3316821
Class-map: voice (match-all)
5590 packets, 3316821 bytes
5 minute offered rate 0 bps, drop rate 0 bps
Match: access-group 105
Priority: 128 kbps, burst bytes 4470, b/w exceed drops: 0
Class-map: class-default (match-any)
270413 packets, 94967696 bytes
5 minute offered rate 7000 bps, drop rate 0 bps
Match: any
Queueing
queue limit 64 packets
(queue depth/total drops/no-buffer drops/flowdrops) 0/147/0/147
(pkts output/bytes output) 270266/94753611
Fair-queue: per-flow queue limit 16
bandwidth 795 kbps
Prima di concludere il post occorre fare una precisazione: ho adoperato un’ACL per la definizione del traffico interessante poichè, in questo modo, lato PBX non è stato necessario effettuare alcuna modifica di configurazione. Infatti, per utilizzare, ad esempio, una class-map così definita:
class-map match-any VOIP-SIGNAL
match ip dscp cs5
match ip precedence 4
match ip precedence 3
class-map match-any VOIP-RTP
match ip dscp ef
match ip precedence 5
sarebbe stato necessario imporre al PBX (Asterisk nel mio caso) di “modificare” il contenuto dell’header dei pacchetti IP (DS Field) applicando un particolare pattern DSCP o un determinato valore di IP Precedence (definendo, nel file sip.conf, delle entry come tos_sip=cs3 per la segnalazione, tos_audio=ef per il traffico RTP audio e tos_video=af41 per il traffico RTP video).
E’ tutto, alla prossima.
PS: La banda che ho definito per il QoS si riferisce ad un’unica chiamata in ingresso/uscita. In particolare, essa dipende strettamente da 2 fattori, ovvero:
1) il numero di chiamate che si vogliono gestire in contemporanea;
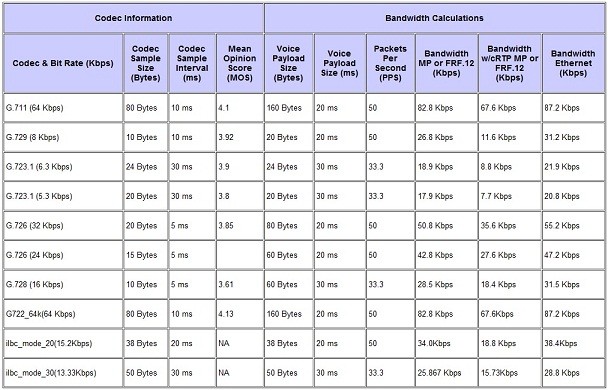
2) il tipo di codec da utilizzare per il traffico voce (specificato all’interno del protocollo SDP, insieme alle porte coinvolte nel traffico RTP). Per maggiori dettagli sulla corrispondenza codec/banda è possibile consultare la seguente tabella:



 Ora, occorre precisare che non è tutto oro ciò che luccica, nel senso che molto spesso i pacchetti ICMP unreachable vengono disabilitati sia in TX che in RX (in questo caso si parla di PMTUD blackhole). Ad esempio, nel caso dei dispositivi di casa Cisco, essi sono disabilitati di default:
Ora, occorre precisare che non è tutto oro ciò che luccica, nel senso che molto spesso i pacchetti ICMP unreachable vengono disabilitati sia in TX che in RX (in questo caso si parla di PMTUD blackhole). Ad esempio, nel caso dei dispositivi di casa Cisco, essi sono disabilitati di default: