In questo post abbiamo visto come configurare Nagios per la ricezione dei check passivi. In quest’altro post, invece, ho spiegato come configurare snmptrapd per la ricezione delle trap SNMP provenienti dai dispositivi monitorati. Adesso vedremo come ricevere su Nagios le suddette trap.
Ingredienti
Oltre a Nagios ed al demone che si occupa della ricezione delle trap (ovvero snmptrapd), è necessario installare sulla macchina che funge da NMS un demone in grado di tradurre le informazioni ricevute in qualcosa di più umanemente comprensibile. Infatti, la difficile interpretazione dei dati riportati dalle trap SNMP rappresenta, sicuramente, uno dei maggiori ostacoli che un sysadmin deve affrontare. Il demone che svolge tale mansione prende il nome di snmptt.
Logica di funzionamento
A grandi linee, il giro del fumo si può riassumere come segue: il dispositivo monitorato genera, di sua sponte, una trap SNMP per segnalare un qualche tipo di anomalia. Essa verrà, successivamente, inoltrata all’NMS, sul quale è attivo il demone snmptrapd (in ascolto sulla porta UDP/162), il quale si occuperà di “passare” tali informazioni ad snmptt. A questo punto, snmptt “tradurrà” i dati che gli sono stati inviati, provvedendo anche inoltrare il relativo output ad uno scrip Nagios (submit_check_result, che potete scaricare da qui) in grado di carpirne il contenuto ed utilizzare quest’ultimo per aggiornare lo stato del servizio dotato di check passivo. Quanto detto fin’ora è riportato (in modo schematico) nell’immagine sottostante.
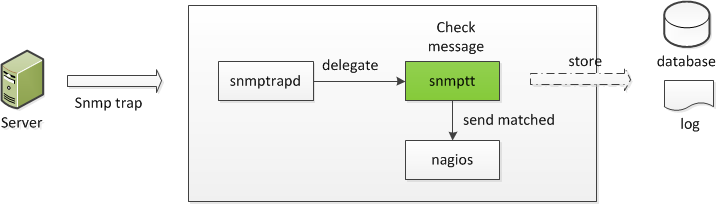
Configurazione di Nagios
Come al solito, il primo step per la realizzazione del nostro ambiente, consiste nella configurazione dell’NMS. Il servizio di monitoraggio delle trap potrà essere simile al seguente:
define service{
use local-service
host_name localhost
service_descripion SNMP TRAP Interceptor
check_command check_passive
passive_checks_enabled 1
active_checks_enabled 0
is_volatile 1
check_freshness 1
freshness_threshold 600
flap_detection_enabled 0
}
mentre il comando check_passive presenterà la seguente struttura:
# 'check_passive' command definition
define command{
command_name check_passive
command_line $USER1$/check_dummy 2 "No alerts received in 600 seconds"
}
Configurazione di snmptrapd
Rispetto alla configurazione vista qui, l’unica variazione consiste nell’aggiunta delle seguente direttiva:
traphandle default /usr/sbin/snmptt
e la configurazione in todo dovrà essere simile alla seguente:
traphandle default /usr/sbin/snmptt authCommunity log,execute,net keypublic format1 %l-%m-%y %h:%j:%k from %A: %b %P %N %W %v\n format2 %l-%m-%y %h:%j:%k from %A: %b %P %N %W %v\n
Installazione e configurazione di snmptt
Per installare il software in questione è sufficiente utilizzare yum:
[root@NMS ~]# yum install snmptt net-snmp-perl
Una volta installato, si può procedere con la sua configurazione mediante l’editing del file /etc/snmp/snmptt.ini. Ecco le modifiche da me apportate:
net_snmp_perl_enable = 1 log_system_enable = 1 log_system_file = /var/log/snmptt/snmpttsystem.log
A questo punto occorrerà procedere con la “traduzione” delle MIB SNMP. Le si può pensare come una sorta di DB testuale, in cui è presente una descrizione “human friendly” di alcuni OID, anche per ciò che concerne le trap.
Il software che svolge tale mansione prende il nome di snmpttconvertmib e si potranno convertire trap presenti nelle MIB lanciando il seguente comando:
[root@NMS ~]# for i in *MIB*;do snmpttconvertmib --in=/usr/share/snmp/mibs/$i --out=/etc/snmp/snmptt.conf --exec='/usr/lib64/nagios/plugins/eventhandlers/submit_check_result $r "SNMP TRAP Interceptor" 1';done
dove i parametri passati a submit_check_result sono:
1) $r, ovvero l’hostname del dispositivo che ha generato la trap;
2) SNMP TRAP Interceptor, ovvero il nome del servizio di Nagios che deve essere aggiornato mediante check passivo;
3) 1, evvero l’exit code da girare all’NMS (che, in tal caso, corrisponderà a WARNING).
Le trap “tradotte” andranno a popolare il file /etc/snmp/snmptt.conf, le cui entry saranno simili alle seguenti:
EVENT ucdShutdown .1.3.6.1.4.1.2021.251.2 "Status Events" Normal FORMAT This trap is sent when the agent terminates $* EXEC /usr/lib64/nagios/plugins/eventhandlers/submit_check_result $r TRAP 1 "This trap is sent when the agent terminates $*" SDESC This trap is sent when the agent terminates Variables: EDESC
Prima di continuare, una piccola nota a margine: per ciò che concerne i dispositivi Cisco, vi consiglio di consultare questo sito (per l’indentificazione ed il download delle MIB) e quest’altro (per la traduzione degli OID).
Inoltre, affinchè lo scrip submit_check_result sia in grado di scrivere all’interno del file nagios.cmd (dove vengono inoltrati tutti i comandi esterni), è necessario sostituire la stringa:
CommandFile="/usr/local/nagios/var/rw/nagios.cmd"
con:
CommandFile="/var/spool/nagios/cmd/nagios.cmd"
A configurazione di snmptt ultimata, possiamo fare in modo che il demone in questione venga eseguito automaticamente al boot:
[root@NMS ~]# chkconfig snmptt on
ed avviarlo:
[root@NMS ~]# service snmptt start
Inoltre, riavviamo snmptrapd per rendere effettive le modifiche apportate in precedenza:
[root@NMS ~]# service snmptrapd restart
e ricarichiamo la configurazione di Nagios:
[root@NMS ~]# service nagios reload
Test e troubleshooting
La prima cosa da fare per capire se snmptt stia funzionando correttamente consiste nell’abilitazione delle opzioni di debug (presenti all’interno di snmptt.ini). Le direttive coinvolte sono le seguenti:
DEBUGGING = 0 DEBUGGING_FILE = /var/log/snmptt/snmptt.debug
Inoltre, è possibile (e opportuno) inviare al nostro handler una trap di test, recante il seguente formato:
[root@NMS ~]# snmptrap -v 1 -c keypublic 127.0.0.1 '.1.3.6.1.6.3.1.1.5.3' '0.0.0.0' 6 33 '55' .1.3.6.1.6.3.1.1.5.3 s “teststring000”
Se la suddetta trap verrà opportunamente gestita da snmptt e dell’event handler di Nagios (submit_check_result), con il successivo aggiornamento del servizio lato NMS, vorrà dire che il nostro sistema sta funzionando come dovrebbe.
Per ora è tutto. Alla prossima.