Qualche tempo fa un mio collega (che svolge tutt’altra mansione rispetto alla mia e che quindi non è un tecnico), mi ha chiesto quale fosse la differenza tra hub e switch, dato che i primi sono ormai quasi del tutto irreperibili sul mercato (a meno di qualche aggeggio usato).
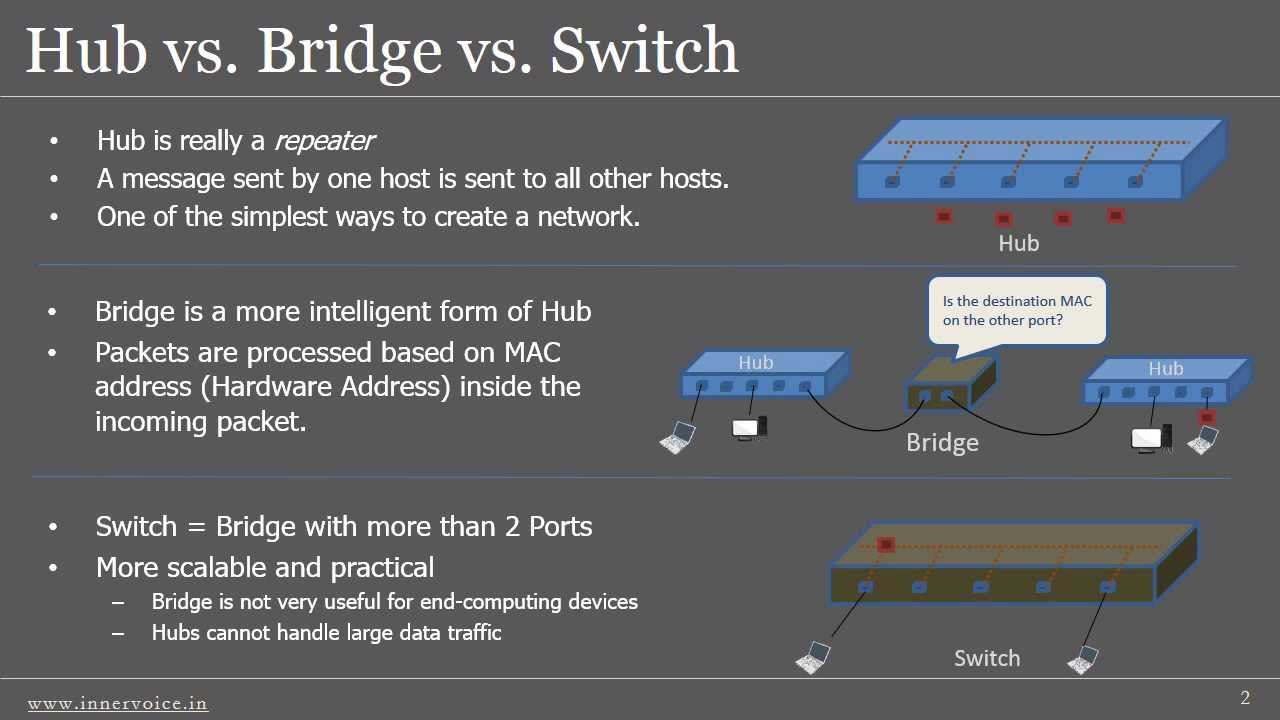
In soldoni, gli hub non sono altro che dei repeater “multiporta” (lasciatemi passare il termine), ovvero il traffico ricevuto su ciascuna porta viene inoltrato, indifferentemente, su tutte le altre. Toccherà poi alle schede di rete dei dispositivi connessi all’hub “capire” se il MAC address di destinazione del frame è il proprio (in questo caso lo accetteranno) oppure è associato a qualche altra macchina, scartandolo. L’ultima affermazione è vera solo ed esclusivamente se la suddetta scheda di rete non è configurata in modalità promiscua. Questa modalità, infatti, le consentirebbe di “accettare” tutti i frame, indifferentemente dal fatto che siano destinati ad essa o meno (e ciò è indispensabile nel caso in cui si voglia sniffare il traffico dei dispositivi connessi all’hub).
Ad esempio, per mettere un’interfaccia in modalità promiscua su una macchina Linux, occorre digitare il comando:
[root@linuxbox ~]# ifconfig <nome_interfaccia> promisc
Inoltre, tale modalità viene abilitata in automatico nel caso in cui sulla Linux box sia installato ed attivo un software che funge da NIDS, quale snort.
Un’altra peculiarità dell’hub riguarda la gestione dei cosiddetti domini di collisione. Infatti, tutti i dispositivi collegati ad esso faranno parte del medesimo dominio di collisione, mentre gli switch, per definizione, riescono a garantire un dominio di collisione ad-hoc per ciascuna porta di cui sono dotati. Per essere più precisi, gli switch sono caratterizzati dalla presenza di una memoria interna, in gergo CAM (acronimo che sta per Content Access Memory), in cui vengono memorizzate le accoppiate MAC address sorgente/porta su cui è stato ricevuto. Tale fase di popolamento della CAM avviene per gradi, ovvero man mano che i dispositivi collegati a ciascuna porta iniziano a trasmettere: quando lo switch vede come MAC sorgente un dato indirizzo L2 su una specifica porta, memorizzerà tale accoppiata all’interno della CAM. Successivamente, quando un frame recante uno specifico MAC di destinazione verrà ricevuto dallo switch, esso lo inoltrerà solo ed esclusivamente sulla porta in cui il dispositivo recante il suddetto MAC è collegato.
Il vantaggio di tale meccanismo di gestione del traffico è abbastanza chiaro: mettendo in comunicazione solo mittente e destinatario, si viene a creare una sorta di “mezzo trasmissivo” dedicato tra di essi, riducendo notevolmente (ma non eliminando completamente) il rischio di collisioni (almeno per quanto riguarda le reti half duplex in cui tale fenomeno può verificarsi). Tirando le somme, è proprio per questo motivo che lo switch “garantisce” un dominio di collisione dedicato per ciascuna porta di cui è dotato. Inoltre, lo sniffing del traffico risulta impossibile, a meno che su una delle porte dello switch sia configurato il cosiddetto port mirroring (che la Cisco chiama SPAN – Catalyst Switched Port Analyzer). Nella fattispecie, essa consente di inoltrare il traffico ricevuto (su una o più porte) su quella in cui è configurato il mirroring (solitamente utilizzo allo scopo l’ultima porta dello switch o le ultime 2). Va da se che anche in questo caso l’interfaccia del PC adibito a sniffer deve essere configurata in modalità promiscua.
Spero di aver fatto un po’ di luce sulla questione.
Alla prossima.