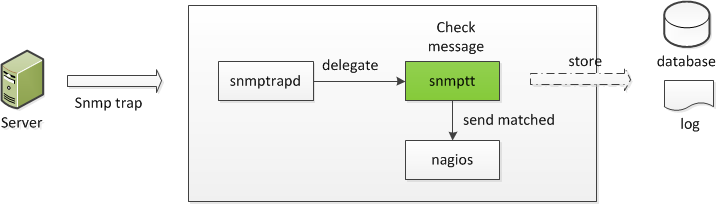
In questo post ho mostrato il codice sorgente del demone barnyard2 da me customizzato. Esso, in soldoni, non fa altro che monitorare il contenuto del file alert generato da snort, in modo da poter individuare gli allarmi creati dall’IDS in questione, inserendoli (dopo un’opportuna formattazione) all’interno di uno specifico DBMS (nel nostro caso MySQL).
Purtroppo, però, tale servizio tende a crashare in modo randomico, ragion per cui ho deciso di creare un event handler (per Nagios) in grado di riavviarlo automaticamente.

Configurazione del SO che ospita L’NMS (Nagios)
Poichè l’operazione di riavvio del demone barnyard2 richiede i privilegi di root, è stato necessario fare in modo che l’utente nagios (che esegue gli event handlers) fosse abilitato all’interno del file /etc/sudoers:
nagios ALL=NOPASSWD: /sbin/service barnyard2 restart
In particolare, ho fatto in modo che l’esecuzione del comando sudo non richiedesse la password (ALL=NOPASSWD:) solo per il comando /sbin/service barnyard2 restart (per la serie less is more). Inoltre, sempre all’interno del suddetto file, ho inserito, subito dopo la direttiva Defaults requiretty, la stringa:
Defaults:nagios !requiretty
in modo tale da consentire all’utente nagios di lanciare il comando sudo anche quando non è in possesso di un terminale (tty). Ciò è necessario poichè tutti gli event handlers vengono lanciati dal nostro NMS in assenza di sessione tty.
Un’altra modifica altrettanto importante ha riguardato SElinux. Esso, infatti, essendo attivo in modalità Enforcing, vietava puntualmente l’esecuzione dell’event handler in questione. Per “aggirare” tale divieto, ho dovuto modificare alcune regole MAC (Mandatory Access Control), attraverso 2 passaggi: il settaggio di una variabile booleana e la creazione di un modulo custom per SElinux.
Nel primo caso è stato sufficiente lanciare il comando:
[root@NMS]# setsebool -P nagios_run_sudo 1
mentre nel secondo caso ho dapprima creato il file permitnagioseventhandlers.te, di cui riporto il contenuto:
module permitnagioseventhandler 1.0;
require {
type nagios_system_plugin_t;
type nagios_unconfined_plugin_exec_t;
type nagios_eventhandler_plugin_t;
type httpd_t;
class file { getattr };
class dir { getattr search };
}
#============= nagios_system_plugin_t ==============
allow nagios_system_plugin_t nagios_unconfined_plugin_exec_t:file {getattr};
#============= httpd_t ==============
allow httpd_t nagios_eventhandler_plugin_t:dir { getattr search };
per poi verificarne la sintassi:
[root@NMS]# checkmodule -M -m -o permitnagioseventhandler.mod permitnagioseventhandler.te
compliarlo:
[root@NMS]# semodule_package -o permitnagioseventhandler.pp -m permitnagioseventhandler.mod
ed installarlo:
[root@NMS]# semodule -i permitnagioseventhandler.pp
Configurazione di Nagios
Il riavvio del demone barnyard2 richiede parecchio tempo (soprattutto se esso è stato associato a più interfacce di rete, come nel mio caso). Per questo motivo si è reso necessario modificare il paramentro event_handler_timeout presente all’interno del file di configurazione Nagios (/etc/nagios/nagios.cfg), portandolo da 30 secondi (valore di default) a 300 secondi:
event_handler_timeout=400
Per ciò che concerne il servizio (relativo al nostro NMS) che si occupa del monitoraggio di barnyard2, è stata creata la seguente configurazione:
define service{
use local-service ; Name of service template to use
host_name localhost
service_descripion Barnyard2 Service Status
check_command check_local_process_status_all!2!2!barnyard2
event_handler restart_barnyard
}
dove il comando check_local_process_status_all è così definito:
# 'check_local_process_status_all' command definition
define command{
command_name check_local_process_status_all
command_line $USER1$/check_procs -c $ARG1$:$ARG2$ -C $ARG3$
}
Nella fattispecie, le variabili $ARG1$ e $ARG2$ rappresentano, rispettivamente, il numero minimo e massimo di processi (recanti la stringa barnyard2, specificata mediante la variabile $ARG3$) attivi sulla macchina da monitorare.
Inoltre, è stato definito il comando restart_barnyard, il cui scopo è quello di eseguire l’event handler in questione:
# 'restart_barnyard' command definition
define command {
command_name restart_barnyard
command_line /usr/lib64/nagios/plugins/eventhandlers/restart_barnyard $SERVICESTATE$ $SERVICESTATETYPE$ $SERVICEATTEMPT$
}
Ho quindi riavviato Nagios per rendere effettive le suddette modifiche:
[root@NMS]# service nagios reload
Contenuto dell’event handler (restart_barnyard)
Una volta completata la fase preliminare relativa alla configurazione del SO e dell’NMS, mi sono dedicato alla creazione dell’event handler vero e proprio (che ho chiamato, molto semplicemente, restart_barnyard). Esso presenta il seguente contenuto:
#!/bin/bash case "$1" in OK) ;; WARNING) ;; UNKNOWN) ;; CRITICAL) case "$2" in SOFT) case "$3" in 3) echo -n "Restarting barnyard2 service (3rd soft critical state)..." /usr/bin/sudo /sbin/service barnyard2 restart ;; esac ;; HARD) echo -n "Restarting barnyard2 service..." /usr/bin/sudo /sbin/service barnyard2 restart ;; esac ;; esac exit 0
ovvero non fa altro che riavviare il servizio in oggetto nel caso del terzo critical state (soft) o del quarto critical state (hard).
L’ho quindi reso eseguibile:
[root@NMS]# chmod +x restart_barnyard
e l’ho salvato all’interno della dir /usr/lib64/nagios/plugins/eventhandlers:
[root@NMS]# mv restart_barnyard /usr/lib64/nagios/plugins/eventhandlers
Test di funzionamento
Infine, ho testato il tutto semplicemente arrestando il servizio barnyard2:
[root@NMS]# service barnyard2 stop
verificando che Nagios svolgesse tutta la trafila per ritirarlo su in modo automatico:
[root@NMS]# tail -f /var/log/nagios/nagios.log
il cui output mi ha mostrato le diverse fasi di passaggio dallo stato CRITICAL allo stato OK:
[1448964811] SERVICE EVENT HANDLER: localhost;Barnyard2 Service Status;CRITICAL;SOFT;3;restart_barnyard [1448965026] SERVICE ALERT: localhost;Barnyard2 Service Status;CRITICAL;HARD;4;PROCS CRITICAL: 0 processes with command name 'barnyard2' [1448965026] SERVICE EVENT HANDLER: localhost;Barnyard2 Service Status;CRITICAL;HARD;4;restart_barnyard [1448965313] SERVICE ALERT: localhost;Barnyard2 Service Status;OK;HARD;4;PROCS OK: 2 processes with command name 'barnyard2' [1448965313] SERVICE EVENT HANDLER: localhost;Barnyard2 Service Status;OK;HARD;4;restart_barnyard
Inoltre, digitando il comando:
[root@NMS]# ps aux | grep barn
ho visualizzato i processi di barnyard2 durante il loro avvio da parte dell’event handler:
nagios 2799 0.0 0.0 108208 1352 ? S 11:17 0:00 /bin/bash /usr/lib64/nagios/plugins/eventhandlers/restart_barnyard CRITICAL HARD 4 root 2800 0.1 0.1 189744 3392 ? S 11:17 0:00 /usr/bin/sudo /sbin/service barnyard2 restart root 2803 0.0 0.0 106460 1680 ? S 11:17 0:00 /bin/sh /sbin/service barnyard2 restart root 2809 0.0 0.0 108568 1868 ? S 11:17 0:00 /bin/sh /etc/init.d/barnyard2 restart root 3194 65.8 1.2 92668 40796 ? Rs 11:18 1:06 barnyard2 -D -c /etc/snort/barnyard2eth0.conf -d /var/log/snort/eth0 -w /var/log/snort/eth0/barnyard2.waldo -l /var/log/snort/eth0 -a /var/log/snort/eth0/archive -f snort.log --pid-path /var/run root 3196 0.0 0.0 108200 1284 ? S 11:18 0:00 /bin/bash -c ulimit -S -c 0 >/dev/null 2>&1 ; barnyard2 -D -c /etc/snort/barnyard2eth1.conf -d /var/log/snort/eth1 -w /var/log/snort/eth1/barnyard2.waldo -l /var/log/snort/eth1 -a /var/log/snort/eth1/archive -f snort.log --pid-path /var/run root 3197 61.4 0.2 58856 7808 ? R 11:18 1:01 barnyard2 -D -c /etc/snort/barnyard2eth1.conf -d /var/log/snort/eth1 -w /var/log/snort/eth1/barnyard2.waldo -l /var/log/snort/eth1 -a /var/log/snort/eth1/archive -f snort.log --pid-path /var/run root 3710 0.0 0.0 103268 864 pts/2 S+ 11:20 0:00 grep barn
E’ tutto. Alla prossima.