Premessa
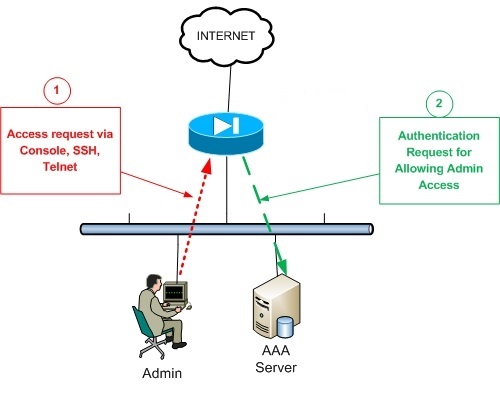
Quando si ha a che fare con reti di grandi dimensioni (che contano centinaia e centinaia di dispositivi connessi tra di loro), occorre fare in modo che gli account utente (ed i relativi permessi) vengano gestiti in modo centralizzato. Tale funzione viene svolta dai cosiddetti server AAA, i quali, mediante l’uso di determinati protocolli (come RADIUS, DIAMETER o TACACS+), forniscono dei meccanismi per l’autenticazione dell’utente (Athentication), per la gestione dei relativi permessi (Authorization) e per la “registrazione” delle azioni compiute dopo aver ottenuto accesso ai dispositivi (Accounting).
Un po’ di teoria
Come già detto in precedenza, i protocolli maggiormente utilizzati per le funzioni AAA sono RADIUS (anche nella variante più recente DIAMETER) e TACACS+.
Il primo è uno standard open, basato sul protocollo UDP, meno sicuro rispetto al TACACS+ (in quanto cifra solo ed esclusivamente il pacchetto che contiene le credenziali di autentica, lasciando il resto delle comunicazioni in plaintext) e che combina in un unico processo i meccanismi di autenticazione ed autorizzazione.
Il secondo, invece, è uno standard basato sul protocollo TCP (porta 49), proprietario (Cisco), più sicuro rispetto al RADIUS (cifra tutti i pacchetti) e che gestisce ciascuna funzione tipica dell’AAA in modo separato e distinto.
Dati i presupposti, la scelta del protocollo da utilizzare nel nostro ambiente ricade abbondantemente su TACACS+ (essendo inoltre di casa Cisco i dispositivi di rete che si intende gestire).
Installazione e configurazione del server AAA
Come si può banalmente evincere dal titolo, il server in questione è stato realizzato utilizzando una Linux box (CentOS 6) con a bordo il demone tac_plus.
Per prima cosa, occorre quindi installare il suddetto applicativo, aggiungendo il repository yum specifico (nux-misc.repo) alla repolist della nostra macchina:
[root@linuxbox ~]# cd /etc/yum.repos.d/
[root@linuxbox ~]# nano nux-misc.repo
il cui contenuto dovrà essere:
[nux-misc]
name=Nux Misc
baseurl=http://li.nux.ro/download/nux/misc/el6/x86_64/
enabled=0
gpgcheck=1
gpgkey=http://li.nux.ro/download/nux/RPM-GPG-KEY-nux.ro
Fatto ciò possiamo procedere con l’installazione vera e propria:
[root@linuxbox ~]# yum --enablerepo=nux-misc install tac_plus
Una volta installato il pacchetto facciamo un backup della sua configurazione di default:
[root@linuxbox ~]# cp /etc/tac_plus.conf /etc/tac_plus.conf.bak
e focalizziamo la nostra attenzione sul file di configurazione che andremo a creare ex-novo:
[root@linuxbox ~]# nano /etc/tac_plus.conf
Il cui contenuto dovrà essere simile al seguente:
key = <passphrase tacacs+>
#ACL
acl = default {
permit = 192\.168\.0\.1
}
# * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
# * ACCOUNTING *
# * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
accounting file = /var/log/tac_accounting.log
#
# * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
# * AUTHENTICATION *
# * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
user = Pippo {
default service = permit
login = des 43v/eMDQqTT2o
member = NOC
}
user = Pluto {
login = des 44LWBaN31RmGg
member = NOC
#AUTHORIZATION ENTRIES
cmd = show {
permit .*
}
cmd = exit {
permit .*
}
}
group = NOC {
acl = default
}
# End config file
Analizziamo il suddetto file. Esistono fondamentalmente due macro sezioni, ovvero authentication ed accounting.
Nella prima ho specificato i 2 utenti (con relativa password) che possono avere accesso ai dispositivi di rete, mentre nella seconda ho indicato il file di log in cui “registrare” tutti gli eventi associati all’accounting.
Da notare che la password degli utenti è in formato DES (cifrata), ed è stata ottenuta utilizzando il tool tac_pwd nel modo seguente:
[root@linuxbox ~]# tac_pwd <salt>
Inoltre, all’interno della sezione authentication, ho inserito, per l’utente Pluto, alcune restrizioni sui comandi che possono essere lanciati. Nella fattispecie, egli potrà utilizzare solo ed esclusivamente i comandi show (il permit = .* indica tutto ciò che viene dopo la keyword show) ed exit. Per quanto riguarda l’utente Pippo, essendoci un deny implicito per il servizio di authorization (quindi tutti i comandi non espressamente dichiarati vengono automaticamente inibiti), ho dovuto aggiungere la direttiva default service = permit.
Da notare che ho inserito anche un’opportuna ACL per fare in modo che solo i dispositivi autorizzati possano dialogare col suddetto demone (ACL coadiuvata da regole di firewalling ad hoc, in modo da rispettare il più possibile il modello defense in depth).
A configurazione ultimata, possiamo avviare il demone:
[root@linuxbox ~]# service tac_plus start
e fare in modo che venga avviato automaticamente dopo ogni reboot:
[root@linuxbox ~]# chkconfig tac_plus on
Come ultimo step relativo alla configurazione del server AAA, sarà necessario creare un’opportuna regola netfilter (utilizzando iptables) per consentire il traffico TACACS+ in ingresso:
-A INPUT -m state --state NEW -m tcp -p tcp -s 192.168.0.1/32 --dport 49 -j ACCEPT -m comment --comment "router"
Configurazione dei dispositivi di rete
Per semplificare un po’ le cose utilizzerò come modello di riferimento la configurazione di un router 2811, anche se essa dovrebbe essere comunque molto simile (se non identica) per la stragrande maggioranza dei dispositivi marchiati Cisco.
Per prima cosa abilitiamo le funzionalità AAA:
Router(config)# aaa new-model
per poi soffermarci sull’autentica:
Router(config)# aaa authentication login default group tacacs+ local
e sulla definizione del server TACACS+ con relativa chiave:
Router(config)# tacacs-server host <ip>
Router(config)# tacacs-server key 0 <pass>
Occorre precisare che l’autenticazione è stata configurata in modo da prevedere un meccanismo di fallback, ovvero nel caso in cui il server AAA non fosse più raggiungibile, sarà comunque possibile loggarsi sul dispositivo utilizzando gli account utente definiti localmente.
Inoltre, nel caso in cui il suddetto server fosse raggiungibile dagli uffici periferici mediante dei tunnel VPN dedicati, occorrerà specificare nella loro configurazione l’interfaccia dalla quale esso puotrà essere contattato:
Router(config)# ip tacacs source-interface <int>
Successivamente possiamo procedere con la configurazione dell’authorization:
aaa authorization exec default group tacacs+ local
aaa authorization commands 1 default group tacacs+ local
aaa authorization commands 15 default group tacacs+ local
e dell’accounting:
Router(config)# aaa accounting system default start-stop group tacacs+
Router(config)# aaa accounting network default start-stop group tacacs+
Router(config)# aaa accounting exec default start-stop group tacacs+
Router(config)# aaa accounting commands 0 default start-stop group tacacs+
Router(config)# aaa accounting commands 15 default start-stop group tacacs+
Router(config)# aaa accounting session-duration ntp-adjusted
Prima di salvare la configurazione, testiamo il corretto funzionamento del meccanismo di autentica, digitando:
Router# test aaa group tacacs+ <user> <pass> legacy
il cui output dovrebbe essere:
Attempting authentication test to server-group tacacs+ using tacacs+
User was successfully authenticated.
Adesso si può finalmente procedere con il salvataggio della configurazione:
Router# copy run start
ed abbiamo finito.
Alla prossima.