Scenario
Server Web Linux (basato su Apache) con CentOS 6 a bordo, dotato di 16 GB di RAM e 2 CPU con 4 core ciascuna. Totale assenza di firewall di frontend, ergo il filtraggio del traffico viene demandato direttamente al server in questione.
Problema
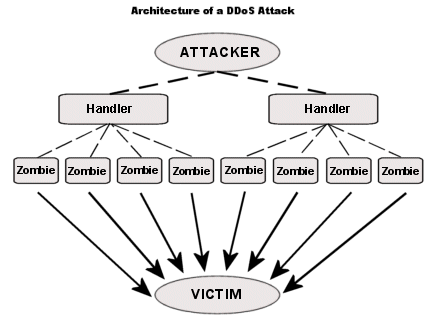
Da N giorni la suddetta macchina è vittima di attacchi di tipo DDoS, provenienti per lo più da IP stranieri (macchine zombie facenti parte di una botnet).
Soluzione
Creare delle regole netfilter ad hoc (mediante iptables), consentendo solo ed esclusivamente i netblock degli ISP italiani. Inoltre, per evitare che l’attaccante possa avvalersi di qualche proxy “aperto” made in Italy, sono stati bloccati ulteriori IP pubblici recuperati da un sito specifico. Infine, sono stati consentiti gli IP pubblici degli spider (aka crawler) utilizzati dai più importanti motori di ricerca (Google, Bing, Yahoo!), in modo tale da impedire che il sito Web hostato sul server venga penalizzato in termini di ranking.
Step 1: consentire gli IP italiani
Lo scrip bash (permit_ita.sh) che esegue tale operazione è il seguente:
#!/bin/bash iptables -A INPUT -p tcp --dport 80 -j DROP iptables -A INPUT -p tcp --dport 443 -j DROP wget http://www.ipdeny.com/ipblocks/data/countries/it.zone -O ip_italiani.txt while read line do iptables -I INPUT -s $line -p tcp --dport 80 -j ACCEPT iptables -I INPUT -s $line -p tcp --dport 443 -j ACCEPT done < ip_italiani.txt iptables-save
Il suo funzionamento è banale: per prima cosa vengono create 2 regole netfilter per droppare tutto il traffico HTTP/HTTPS diretto al sito Web. Successivamente viene scaricato (mediante wget) il contenuto del sito http://www.ip-deny.com/ipblocks/data/countries/it.zone, in cui è presente l’elenco dei netblock italiani. Infine, vegnono consentiti i netblock in questione.
Step 2: bloccare i proxy made in Italy
A questo punto possiamo procedere con il blocco dei proxy “open” italiani. Per fare ciò possiamo utilizzare il seguente scrip bash (block_proxy.sh):
#!/bin/bash
wget --user-agent="Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.3) Gecko/2008092416 Firefox/3.0.3" http://spys.ru/free-proxy-list/IT/ -O lista_proxy.txt
grep -E -o "([0-9]{1,3}[\.]){3}[0-9]{1,3}" lista_proxy.txt | uniq > ip_proxy.txt
while read line
do
iptables -I INPUT -s $line -p tcp --dport 80 -j DROP
iptables -I INPUT -s $line -p tcp --dport 443 -j DROP
done < ip_proxy.txt
iptables-save
Il sito target (ovvero quello che contiene la lista dei proxy da bloccare) è http://spys.ru/free-proxy-list/IT/, il quale effettua un filtraggio dei client che possono accedervi utilizzando lo User Agent come discriminante (quindi non è possibile scaricarne il contenuto se non si effettua uno spoofing di tale parametro tramite wget e l’opzione –user-agent).
Inoltre, poichè il contenuto del sito non è una “lista piatta” di IP pubblici, è stato necessario filtrare il tutto utilizzando un’espressione regolare in grado di individuare i 4 ottetti tipici dell’IPv4.
Step 3: consentire gli spider dei motori di ricerca
Come ultima fase, occorre consentire gli IP degli spider, utilizzando tale scrip (permit_spider.sh):
#!/bin/bash while read line do iptables -I INPUT -s $line -p tcp --dport 80 -j ACCEPT -m comment --comment "crawler" done < ip_spider.txt iptables-save
Il contenuto del file ip_spider.txt potete ricavarlo da qui (Google), qui (Yahoo!) e qui (Bing ed altri).
A configurazione completata, possiamo saggiare il carico sul server (intento a droppare il traffico proveniente dalla botnet) utilizzando htop.
Se la macchina regge e le risorse hardware locali non sono allo stremo potremo finalmente dire di aver vinto.
Alla prossima.