Un buffer non è altro che una sequenza di lunghezza predefinita di celle di memoria (per semplicità lo si può intendere come un array). Quando si cerca di allocare delle variabili al di fuori dei limiti di tale array si parla proprio di buffer overflow (dove overflow significa straripamento).
Alcuni linguaggi di programmazione (come Java) effettuano un controllo sul corretto utilizzo del buffer, segnalando eventuali anomalie durante la fase di runtime (ovvero durante l’esecuzione del programma). Altri linguaggi invece, quali C o C++, non operano alcun controllo sulla corretta allocazione delle variabili, che quindi possono essere posizionate in indirizzi di memoria “dedicati” ad altri processi. Sfruttando proprio questa vulnerabilità un utente malevolo potrebbe eseguire del codice arbitrario sul calcolatore della vittima, compromettendone il livello di sicurezza.
Uno degli esempi più diffusi di buffer overflow è lo stack overflow. In particolare, uno stack (che letteralmente significa catasta) è una regione di memoria che viene gestita come una coda LIFO (Last Input – First Output), in cui push (inserimento) e pop (estrazione) sono le uniche operazioni consentite.
Il verificarsi di questo tipo di anomalia è in qualche modo incentivato dal fatto che in moltissime architetture (tra le quali x86), la memoria “cresce” (ovvero viene allocata) in un senso, mentre lo stack viene riempito nel senso opposto. Per focalizzare meglio il problema esaminiamo il seguente codice (scritto in C):
#include <string.h>
void foo (char *bar)
{
char c[12];
memcpy(c, bar, strlen(bar)); // no bounds checking...
}
int main (int argc, char **argv)
{
foo(argv[1]);
return 0;
}
Questo programmino non fa altro che ricevere da shell una stringa di massimo 12 caratteri (in teoria) e la salva all’interno dello stack dedicato alla funzione foo(). Tale operazione viene effettuata proprio dalla funzione memcpy(), il cui argomento è costituito dalle variabili c (ovvero la stringa), bar e della lunghezza di quest’ultima, calcolata mediante la funzione strlen(). Occorre notare però che memcpy() non effettua alcun controllo relativo ai limiti del buffer, ecco perchè viene usato questo codice come esempio di programma soggetto a stack overflow.
Si focalizzi ora l’attenzione sulla variabile char c[12]. Essa non è altro che un array di 13 posizioni (da 0 a 12) che però può contenere soltanto 12 caratteri, in quanto il linguaggio C aggiunge automaticamente il carattere tappo per indicare la fine della stringa.
Quando vado ad inserire tramite shell la stringa hello, il main() richiamerà la funzione foo() (solo dopo averne preparato il record di attivazione), il cui stack ci apparirà nel seguente modo:
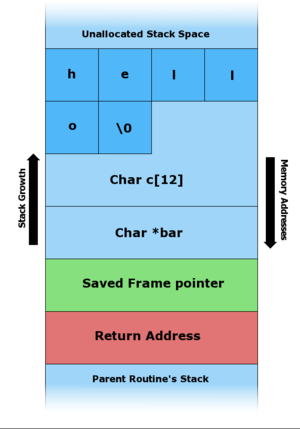
dove Return Address è l’indirizzo della prossima istruzione da eseguire, Saved Frame Pointer punta alla fine dello stack precedente (ovvero quello della funzione main()), in modo da consentire al programma di risposizionarsi su di esso dopo aver deallocato il record della funzione foo(), e char *bar contiene l’indirizzo della variabile bar (l’asterisco indica che ho a che fare con un puntatore).
Supponiamo ora di andare ad inserire la seguente stringa: “AAAAAAAAAAAAAAAAAAAAx08x35xC0x80”. Lo stack della funzione foo() avrà questa conformazione:
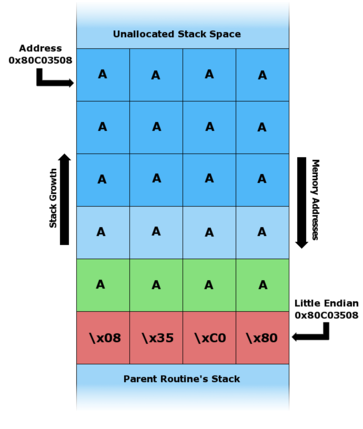
Come potete notare, il campo dello stack che serviva a restiture il controllo al main() una volta terminata l’esecuzione di foo(), ovvero Saved Frame Pointer, viene sovrascritto, e stessa sorte tocca a Return Address, all’interno del quale viene salvato il seguente indirizzo (in notazione little endian, cioè le cifre più significative sono a destra):
"x08x35xC0x80"
Questo indirizzo potrebbe puntare ad una locazione di memoria in cui è presente del codice macchina malevolo, e quindi potrebbe consentire ad un eventuale attaccker di ottenere il controllo del sistema remoto.
Esistono comunque diverse tecniche per cercare di prevenire gli attacchi basati su stack overflow. Una di queste (utilizzata nell’ambito dell’architettura SPARC), fa in modo che la memoria e lo stack vengano riempiti seguendo lo stesso verso. In questo modo i “dati in eccesso” non andranno a sovrascrivere alcune delle parti fondamentali dello stack, ma si posizioneranno al di fuori di esso. Tale soluzione però è alquanto “grezza”, poichè potrebbe esserci un altro stack limitrofo a quello considerato, portando a sovrascrivere il suo Saved Frame Pointer oppure il suo Return Address.
Un’altra soluzione consiste nell’usare alcune liberie C e C++ reimplementate (ed a pagamento), le quali, a differenza di quelle standard, garantiscono meccanismi di controllo del buffer.
Si possono usare inoltre delle tecniche per la protezione del puntatore, andando a crittografare mediante un semplice XOR alcuni indirizzi di memoria considerati “sensibili”.
Occorre mensionare anche la tecnica denominata non executable stack. Essa fa in modo che non possa essere eseguito del codice arbitrario (in particolare codice macchina) direttamente dallo stack, basando il suo funzionamento su un bit implementato a livello di CPU, denominato NX (No Execute). In teoria si potrebbe resettare il valore di questo bit impostandolo a 0, anche se nessuno è ancora riuscito a farlo. E’ comunque possibile eludere tale tecnica di protezione seguendo due strade: iniettare il codice macchina in porzioni di memoria non protette (come l’heap), oppure sfruttare dei programmi già allocati in memoria per effettuare chiamate utili all’attacker (ad esempio system(), che consente di eseguire codice arbitrario). Quest’ultima tecnica prende il nome di return-to-libc, in riferimento al fatto che nei sistemi UNIX like, appena un qualunque programma scritto in C viene mandato in esecuzione, la libreria libc automaticamente viene posizionata in memoria.
Ma cosa succede quando l’attaccante non conosce a priori l’indirizzo delle istruzioni malevole da eseguire sull’host remoto? Semplicemente riempie la memoria con una serie di istruzioni no op (ovvero no operation, 0x90 nelle architetture x86), fino ad arrivare all’indirizzo desiderato. Tale tecnica prende il nome di nop sled.
Il post termina qui. A presto.
Sono riuscito a trovare un programma che risolve questo problema ed in più è indipendente dalla piattaforma e dal compilatore.
Lo si può scaricare da http://www.bugfighter-soft.com
A quanto ho capito è un parser che converte il proprio codice sorgente in un nuovo codice sorgente che poi può essere compilato: http://www.bugfighter-soft.com/images/BugFighter.jpg
Riesce perfino a individuare gli indici errati nei vettori multipli:
char vett[5][5][5];
vett[1][6][0] = 9;
scrive su file che il secondo indice è errato.
Saluti
Ciao Luca. Ottima segnalazione, nei prossimi giorni vedrò di approfondire la cosa, ma per quello che mi hai detto sembra che questo programmino sia davvero interessante…