In questo post abbiamo visto cosa si intende per MAC (Message Authentication Code) e come esso venga realizzato mediante alcune tecniche HASH. Adesso ci soffermeremo sul progetto HMAC, il cui scopo è quello di consentire l’uso di un qualunque algoritmo di cifratura one-way per l’autenticazione dei messaggi.
Ma perchè utilizzare algoritmi HASH con scopi di autenticazione di messaggio? Perchè sono ottimizzati per la loro esecuzione a livello software e sono facilmente reperibili su Internet sottoforma di librerie. Nonostante ciò, essi presentano una limitazione, ovvero non utilizzano una chiave segreta e quindi non possono essere direttamente utilizzati nell’ambito del MAC.
Ecco allora che proprio per sopperire a tale limitazione viene realizzato il progetto HMAC. Esso, in sintesi, si prefigge 5 obiettivi, ovvero:
1) utilizzare, senza procedere con la loro modifica, le funzioni HASH già esistenti (soprattutto quelle caratterizzate da buone prestazioni software);
2) sostituire facilmente, in caso di necessità, la funzione HASH utilizzata con un’altra che prevede migliori prestazioni ed una maggiore robustezza;
3) preservare le prestazioni originarie HASH ;
4) gestire facilmente le chiavi segrete;
5) garantire un elevato livello di sicurezza, anche grazie alle caratteristiche intrinseche dell’algoritmo di cifratura one-way utilizzato.
I primi due punti sono garantiti dall’HMAC, poichè esso vede la funzione HASH come una scatola nera. In questo modo, anche nel caso in cui la sicurezza della funzione di cifratura fosse compromessa, la si potrebbe sostituire facilmente.
Inoltre, il meccanismo HMAC può considerarsi sicuro nel momento in cui l’algoritmo di cifratura one-way è sicuro.
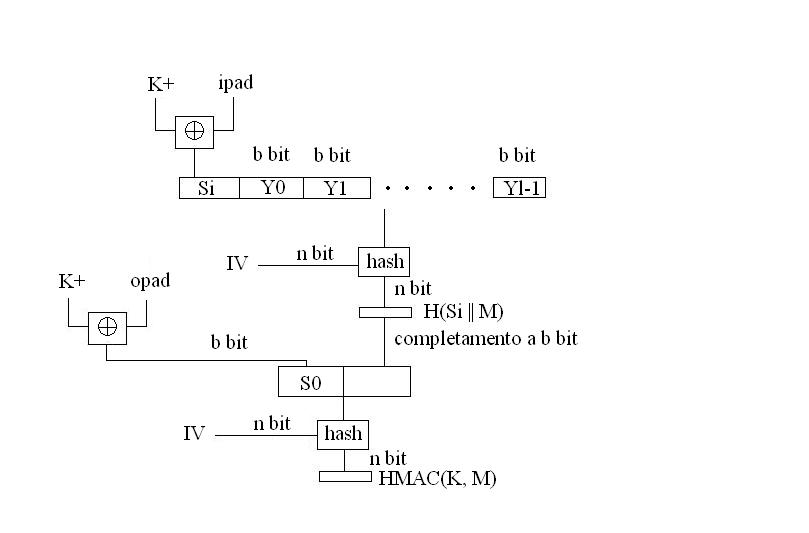
Vediamo adesso qual è il funzionamento complessivo di HMAC:
dove:
1) il blocco “hash” rappresenta la funzione hash contenuta (ad esempio MD5);
2) M rappresenta il messaggio in ingresso ad HMAC;
3) L rappresenta il numero di blocchi in cui è stato suddiviso il messaggio M;
4) Yi rappresenta l’i-esimo blocco di M, con 0 <= i <= (L-1)
5) b è il numero di bit di un blocco;
6) n è la lunghezza del codice HASH prodotto dalla funzione di cifratura one-way contenuta;
7) K è la chiave segreta: se la lunghezza della chiave è maggiore di b, allora essa verrà data in pasto alla funzione HASH per generare il digest di n bit; la lunghezza consigliata è >= n.
8) K+ è la chiave completata con una serie di zeri a sinistra (padding) in modo da raggiungere la lunghezza minima indispensabile, ovvero b bit;
9) ipad è pari a 00110110 (36 in hex) ripetuto b/8 volte (se ad esempio b=16 avrò 0011011000110110, ovvero 00110110 ripetuto due volte);
10) opad è pari a 01011100 (5C in hex) ripetuto b/8 volte;
Il byte che identifica opad ed ipad viene ripetuto b/8 volte poichè non è possibile “xorare” sequenze di bit di lunghezza diversa.
Ecco, nello specifico, le operazioni effettuate nell’ambito dell’HMAC:
1) aggiungo una serie di 0 a sinistra della chiave K per ottenere la lunghezza minima di b bit, in questo modo otterrò K+;
2) effettuo lo XOR tra K+ e l’ipad;
3) accodo al risultato dello XOR, ovvero Si, il messaggio M suddiviso in L blocchi dalla lunghezza di b bit;
4) applico la funzione HASH ad (Si || M), sfruttando un opportuno vettore di inizializzazione IV;
5) se l’HASH generato ha dimensione inferiore a b bit effettuo uno zero-padding portando la sua lunghezza a b bit;
6) calcolo lo XOR tra K+ e l’opad, generando S0;
7) accodo ad S0 l’hash precedentemente generato e il risultato di tale operazione lo do in pasto alla funzione HASH, inizializzata mediante il cosiddetto IV;
8) ottengo HMAC(K,M) (costituito da n bit).
Queste operazioni possono essere riassunte nella formula:
HMAC(K, M)= H[(K+ XOR opad) || H[(K+ XOR ipad || M–
Da notare che i tempi di esecuzione di HMAC sono approssimativamente uguali a quelli della funzione HASH utilizzata.
A presto.