Gli attacchi DoS (Denial of Service) e DDoS (Distribuited Denial of Service) rappresentano uno dei fenomeni più preoccupanti degli ultimi anni. Infatti, non è raro incappare in siti e portali di vario genere i cui tempi di risposta risultano mostruosamente alti, causando diversi problemi alla navigazione degli utenti legittimi e, in alcuni casi, l’irraggiungibilità del sito stesso.
Le motivazioni che stanno dietro a questa tipologia di attacco sono le più disparate:
1) motivazioni di tipo economico. Un’azienda potrebbe decidere di “investire” del denaro per cercare di arrecare danno al business di una società rivale, che magari opera nello stesso settore, soprattutto se la maggior parte dei proventi di quest’ultima derivano da un portale di e-commerce;
2) motivazioni di tipo logistico/strategico. Si potrebbe, ad esempio, costringere la comunità di un forum a “migrare” su un altro portale, promettendo in cambio la stabilità dei servizi offerti ed il ripristino della raggiungibilità del sito 24/7;
3) motivazioni di tipo politico/religioso. E’ sempre più frequente assistere ad attacchi di negazione del servizio diretti verso portali in cui viene manifestato un determinato orientamento politico/religioso.
Occorre precisare, inoltre, che con l’aumento della capacità di calcolo degli elaboratori e con l’incremento dell’ampiezza banda offerta dai vari ISP, gli attacchi DoS, ovvero quelli provenienti da un singolo host, stanno diventando obsoleti e del tutto inefficaci. Viceversa , gli attacchi di negazione del servizio distribuiti (DDoS) continuano a rappresentare una serie minaccia nell’ambito dell’IT security, poichè riescono a saturare in pochissimo tempo le risorse dell’host vittima, causandone l’irraggiungibilità.
Classificazione degli attacchi e tecniche
Esistono diversi metodi per classificare gli attacchi DDoS ed uno di questi si basa proprio sul tipo di risorsa che l’attacco stesso tenta di consumare. Tale risorsa può essere rappresentata dalla CPU, dalla RAM o dalla memoria di massa su cui è installato il sistema operativo, oppure dalla capacità di tx/rx dell’host vittima. In quest’ultimo caso, una tecnica ampiamente utilizzata si basa proprio sulla struttura del protocollo TCP/IP e prende il nome di SYN-flood. Per capire bene come un attacco SYN flood viene perpetrato occorre fare un esempio:
Supponiamo che l’utente legittimo A voglia collegarsi al portale Web B.
1) Per prima cosa l’host A invia un pacchetto TCP/IP di tipo SYN, ovvero richiede la sincronizzazzione con il portale stesso, la quale si basa essenzialmente sullo scambio di un numero di sequenza iniziale (ISN – Initial Sequence Number). Il numero di sequenza iniziale è fondamentale, in quanto tutti gli altri pacchetti scambiati tra i due host in questione verranno identificati mediante un numero di sequenza incrementale, successivo all’ISN. Ma a cosa serve effettivamente il numero di sequenza? Serve semplicemente a ricostruire correttamente le informazioni ricevute, nel caso in cui esse non siano giunte a destinazione nel giusto ordine (ecco perchè il protocollo TCP è definito “affidabile”);
2) una volta che il portale Web, ovvero B, riceve il pacchetto SYN, risponde all’host A inviando un pacchetto SYN/ACK (leggasi riscontro di sincronizzazione);
3) infine, dopo aver ricevuto il SYN/ACK, l’host A invia al portale Web B un ulteriore pacchetto di riscontro, detto ACK, completando così la procedura di connessione (ecco perchè il protocollo TCP si dice “basato su connessione”).
L’insieme degli step 1), 2) e 3) rappresenta il cosiddetto three-way handshake, necessario affinchè una connessione TCP venga instaurata.
Supponiamo ora che un eventuale attaccante, ovvero C, voglia scagliare un DDoS verso il portale B. Esso per prima cosa forgerà dei pacchetti TCP/IP di tipo SYN, falsificando l’indirizzo IP mittente, magari inserendone uno inesistente. Il server Web risponderà ai pacchetti SYN inviando dei SYN/ACK verso l’IP inesistente, lasciando la connessione in buffer fino alla ricezione dell’ACK.
Ovviamente, tale ACK non verrà mai ricevuto, proprio perchè l’indirizzo IP a cui è stato inviato il SYN/ACK è inesistente (parliamo allora di connessioni mezze-aperte, dette anche half-open). Quindi, se il numero di pacchetti SYN inviati all’host vittima è abbastanza elevato e se i tempi di timeout delle connessioni TCP half-open sono troppo alti (per un errata configurazione del server), il portale Web si ritroverà con il buffer completamente saturo, e non sarà più in grado di accettare connessioni basate sul protocollo TCP, anche se legittime.
Recentemente, sono state sviluppate altre tecniche che puntano a saturare la capacità di tx/rx degli host vittima. Tra queste vi sono le connessioni half-closed e gli attacchi scan.
Nel primo caso, l’attaccante, ovvero C, crea delle connessioni legittime e di breve durata con il portale Web B. Successivamente, cerca di abbattere tali connessioni inviando dei pacchetti FIN all’host vittima. Quest’ultimo invierà all’attaccante un pacchetto FIN/ACK e successivamente rimarrà in attesa dell’ACK finale che causerà la disconnessione vera e propria. Se però, come nel caso delle connessioni half-open, l’ultimo ACK tarda ad arrivare ed il numero di pacchetti FIN è piuttosto elevato, il buffer tenderà ad esurirsi abbastanza velocemente causando disservizio.
Nel caso degli attacchi scan, invece, la negazione del servizio viene realizzata semplicemente usando i cosiddetti port-scan. Nella fattispecie, i port-scan vengono adoperati durante la fase preliminare di un attacco, detta footprinting o ricognizione, grazie alla quale è possibile identificare i tipi di servizi presenti sull’host vittima. Ogni servizio è in ascolto su una determinata porta ed in base a quest’ultima è possibile farsi un’idea di quali siano effettivamente i servizi pubblicati sul server che si sta scansionando. Ora, qui è necessario fare alcune precisazioni:
1) Esistono le cosiddette well-known port, che vanno dalla 1 alla 1023. Esse sono riservate a determinati servizi, come POP3 (110), SMTP (25), Telnet (23), FTP (20-21), SSH (22) e così via. Non è raro, però, che gli amministratori di sistema utilizzino delle porte non standard per la pubblicazione dei servizi (ad esempio mettendo in ascolto il server SSH su una porta > 1023 anzichè sulla 22). In questo modo si evita che script di scansione automatizzati individuino servizi in ascolto su porte standard e tentino automaticamente il login, perpetrando un attacco bruteforce basato su dizionario.
2) Alla luce di quanto appena detto, non è raro che i port-scan producano come risultato dei falsi positivi.
Ma vediamo adesso come funzionano i cosiddetti scan-attack. Quando viene effettuata una ricognizione mediante degli appositi tool (ad esempio nmap), vengono “simulate” delle connessioni sulle 1023 well-known port dell’host vittima, riuscendo in questo modo ad identificare su quali esso risulta effettivamente in ascolto. Ovviamente tale procedura genera del traffico e se i tentativi di scansione si ripetono ad intervalli di tempo brevissimi e se provengono da un numero abbastanza elevato di host (magari dotati di un’ampiezza di banda non indifferente), essi causeranno inevitabilmente un riempimento del buffer della vittima e quindi una probabile negazione del servizio. Inoltre, per aumentare ulteriormente la frequenza degli scan e quindi la mole complessiva degli stessi, può essere utilizzanto il protocollo UDP (mediente la flag -sU di nmap), il quale, a differenza del protocollo TCP, non prevede l’instaurazione di una connessione vera e propria, con tempi di tx/rx estremamente ridotti e quindi con maggiore probabilità di saturare il buffer.
Un altro criterio usato per la classificazione degli attacchi DDoS tiene conto della capacità dell’attaccante di “reclutare” nuove macchine dalle quali veicolare l’attacco vero e proprio. In particolare, parliamo di attacco DDoS diretto quando è proprio l’attaccante ad installare su alcune macchine vittima un software sviluppato ad hoc (solitamente un worm) che gli consentirà di ottenerne il controllo da remoto. Tali macchine diverranno quindi “zombie” ed andranno a far parte di un insieme di elaboratori infetti, chiamato botnet (o dosnet).
Sovente gli attacchi DDoS coinvolgono due livelli di macchine zombie: gli zombie master e gli zombie slave, dove i primi coordinano l’operato dei secondi. L’uso di due livelli di zombie rende più difficile l’identificazione della vera sorgente dell’attacco e fornisce una rete di host attaccanti più flessibile.

Un attacco DDoS tramite riflettori (DRDoS) aggiunge un ulteriore livello di macchine, che andranno ad aggiungersi agli zombie master e slave.
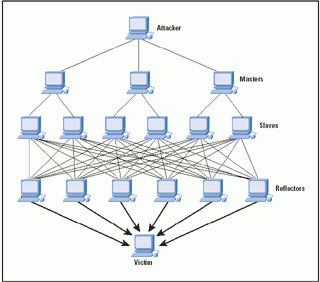
In questo caso, però, gli elaboratori che fungono da riflettori non sono delle macchine infette. Semplicemente, gli zombie slave, veicolati dagli zombie master, generano delle richieste contenenti come IP sorgente quello del portale Web vittima (B). Tali richieste verranno indirizzate verso i riflettori che risponderanno direttamente alla macchina bersaglio. Un attacco di questo tipo è sicuramente il più subdolo ed allo stesso tempo il più dannoso: subdolo perchè l’uso di macchine non infette come front-end dell’attacco rende ancora più difficile l’individuazione del vero attaccante, dannoso poichè a seconda del numero di macchine riflettori coinvolte, la mole di traffico diretta verso l’host vittima potrebbe essere di una portata tale da causare una negazione del servizio pressocchè immediata.
Costruzione di una rete di attacco
Durante la prima fase di un attacco DDoS, l’aggressore infetterà molte macchine tramite software zombie, in modo tale da ottenerne il controllo ed utilizzarle successivamente come teste di ponte durante l’attacco vero e proprio. Affinchè tale operazione vada a buon fine è necessario che vengano rispettate le seguenti condizioni:
1) il software che viene usato per infettare le macchine deve essere in grado di girare su un elevato numero di elaboratori, di nascondere la sua esistenza, di comunicare con l’attaccante oppure di essere dotato di un qualche tipo di meccanismo a innesco temporale, oltre, ovviamente, ad essere capace di veicolare l’attacco verso il bersaglio;
2) il software deve basarsi su una vulnerabilità molto diffusa ma che allo stesso tempo è stata trascurata da molti utenti/amministratori di sistema;
Inoltre, gli host vulnerabili vengono individuati mediante un’operazione di scansione, la quale può avere le seguenti caratteristiche:
1) potrebbe essere casuale, ovvero l’attaccante esamina degli indirizzi IP random, usando di volta in volta un seme differente;
2) potrebbe essere basata su una hit-list, ovvero su una lista di macchine potenzialmente vulnerabili;
3) potrebbe essere topologica, ovvero l’attaccante utilizza le informazioni contenute su una macchina già infetta per trovare altri host vulnerabili.
Nei prossimi giorni andremo ad esaminare in dettaglio quali sono le tecniche per mitigare, se non contrastare, attacchi di questo genere.
A presto.