Solitamente, prima di mettere in produzione una Web application, si rende necessario testarla in modo approfondito su di un ambiente apposito, in modo da ridurre al minimo eventuali problemi/disservizi riscontrati dagli utenti che intendono utilizzarla.
Tralasciando i veri test che puntano esclusivamente sull’usabilità e sul corretto funzionamento della Web application in quanto tale (oltre, ovviamente, agli aspetti legati alla sicurezza), è indispensabile effettuare delle prove di carico sul server Web che la ospita (o, in alternativa, sull’application server).
In questo post vi mostrerò come effettuare dei test di carico mediante due tool nati per questo scopo, ovvero httperf ed ab (aka Apache Benchmark).
Installiamo dunque gli applicativi menzionati in precedenza. Il primo potete scaricarlo da qui (CentOS x86_64), mentre il secondo si trova all’interno del package httpd, installabile mediante un semplice packet manager (ad esempio yum):
[root@client ~]# yum install httpd
Per installare httperf (dopo averlo scaricato), potete lanciare il comando:
[root@client ~]# rpm -ivh httperf-0.9.0-1.el6.rf.x86_64.rpm
A questo punto possiamo dare inizio ai nostri test. Per prima cosa faremo delle prove sul server lato utente anonimo, ovvero simuleremo il traffico generato da tutti gli utenti che non hanno ancora effettuato il login (sempre che la nostra Web application lo preveda).
[root@client ~]# httperf --server=ipserverweb --uri=/ --num-conn 12000 --num-call 50 --rate 300 --timeout 5
In questo modo stiamo simulando un numero massimo di 12000 connessioni, ciascuna delle quali effettua 50 chiamate HTTP, ogni sencondo vengono effettuate 300 nuove connessioni (fino al tetto massimo di 12000) ed il timeout di ciascuna connessione è pari a 5 secondi.
Secondo questa logica, possono essere effettuati test di carico ancora più consistenti, ad esempio:
[root@client ~]# httperf --server=ipserverweb --uri=/ --num-conn 50000 --num-call 500 --rate 300 --timeout 30
o ancora:
[root@client ~]# httperf --server=ipserverweb --uri=/ --num-conn 100000 --num-call 1000 --rate 500 --timeout 60
I risultati dei suddetti test ci appariranno in un formato simile al seguente:
Total: connections 4996 requests 249800 replies 249800 test-duration 44.835 s Connection rate: 111.4 conn/s (9.0 ms/conn, <=1022 concurrent connections) Connection time [ms]: min 65.0 avg 8439.3 max 12570.1 median 8742.5 stddev 1720.6 Connection time [ms]: connect 0.1 Connection length [replies/conn]: 50.000 Request rate: 5571.6 req/s (0.2 ms/req) Request size [B]: 59.0 Reply rate [replies/s]: min 5557.4 avg 5571.4 max 5585.2 stddev 10.5 (8 samples) Reply time [ms]: response 168.7 transfer 0.1 Reply size [B]: header 229.0 content 5043.0 footer 0.0 (total 5272.0) Reply status: 1xx=0 2xx=0 3xx=0 4xx=249800 5xx=0 CPU time [s]: user 0.87 system 43.96 (user 1.9% system 98.0% total 100.0%) Net I/O: 29005.9 KB/s (237.6*10^6 bps) Errors: total 7004 client-timo 0 socket-timo 0 connrefused 0 connreset 0 Errors: fd-unavail 7004 addrunavail 0 ftab-full 0 other 0
Le informazioni presenti nel suddetto report sono lapalissiane e possono tornarci di grande aiuto per ciò che concerne il traffico che il nostro server Web è in grado di reggere.
Nel frattempo, durante i suddetti test, è importante tenere sotto controllo due fattori:
1) l’effettiva raggiungibilità del sito (facendo delle prove di connessione mediante un semplice browser);
2) l’utilizzo delle risorse locali (RAM e CPU). A tal proposito vi consiglio di utilizzare uno strumento abbastanza semplice e più evoluto rispetto al comando top, ovvero htop:
[root@client ~]# yum install htop
La schermata che vi apparirà sarà simile alla seguente:
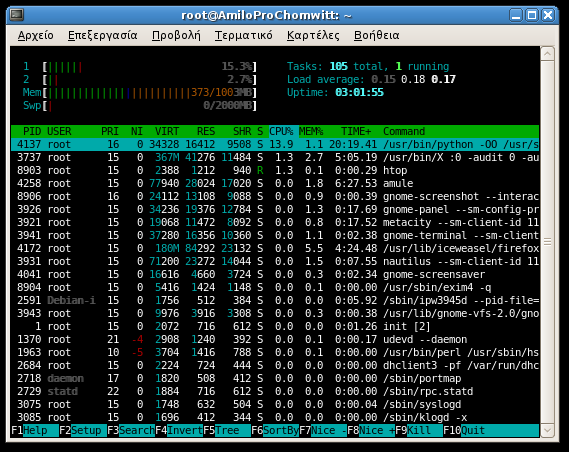
Terminati i test lato utente anonimo, iniziamo con quelli lato utente loggato (che sicuramente stresseranno maggiormente la nostra macchina). Infatti, durante questi test verranno processate le chiamate server side (PHP, Jsp, ASP, C# et similia, a seconda della tecnologia utilizzata per implementare la Web application), allocando grosse quantità di RAM (e parte della swap) e facendo lavorare intensamente la (oppure le) CPU.
Come già accennato in precedenza, è possibile effettuare dei test lato utente loggato utilizzando un tool messo a disposizione dell’Apache Software Foundation, ovvero Apache Benchmark (ab). Nella fattispecie, la flag da utilizzare è -C ed usa come argomento il contenuto dell’authentication cookie rilasciato dalla nostra applicazione Web (potete utilizzare questo add-on di Mozilla Firefox in grado di leggere il contenuto del cookie in questione).
Ecco un esempio:
[root@client ~]# ab -n 2 -C "contenuto dell'authentication cookie" http://sitodatestare/
Con la flag -n sto indicando il numero di connessioni che devono essere simulate. Inoltre, i vari campi che compongono l’auth cookie devono essere intervallati da un ; mentre il valore di ciascun campo deve essere preceduto da un =. Ad esempio:
[root@client ~]# ab -n 2 -C "has_js=1; pri_num=3" http://sitodatestare/
Come avrete facilmente intuito, nell’esempio viene effettuato un test molto blando. Passiamo adesso ad alcune prove più impegnative (in termini di carico), utilizzando la flag -c che ha il compito di simulare le connessioni contemporanee:
[root@client ~]# ab -n 20 -c 10 -C "contenuto dell'authentication cookie" http://sitodatestare/
e ancora:
[root@client ~]# ab -n 210 -c 200 -C "contenuto dell'authentication cookie" http://sitodatestare/
e così via.
Il report generato avrà il seguente formato:
Benchmarking *.*.com (be patient) Completed 100 requests Completed 200 requests Finished 210 requests Server Software: Apache/2.2.3 Server Hostname: *.*.com Server Port: 80 Document Path: / Document Length: 36020 bytes Concurrency Level: 210 Time taken for tests: 89.815037 seconds Complete requests: 210 Failed requests: 15 (Connect: 0, Length: 15, Exceptions: 0) Write errors: 0 Non-2xx responses: 15 Total transferred: 7129290 bytes HTML transferred: 7030005 bytes Requests per second: 2.34 [#/sec] (mean) Time per request: 89815.039 [ms] (mean) Time per request: 427.691 [ms] (mean, across all concurrent requests) Transfer rate: 77.51 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 0 0 1.3 1 2 Processing: 1748 54696 18359.3 58915 89812 Waiting: 1747 54695 18359.3 58914 89811 Total: 1748 54697 18359.2 58916 89814 Percentage of the requests served within a certain time (ms) 50% 58916 66% 64830 75% 69917 80% 71274 90% 76405 95% 77879 98% 79840 99% 80893 100% 89814 (longest request)
Questo è quanto, buon benchmarking.





