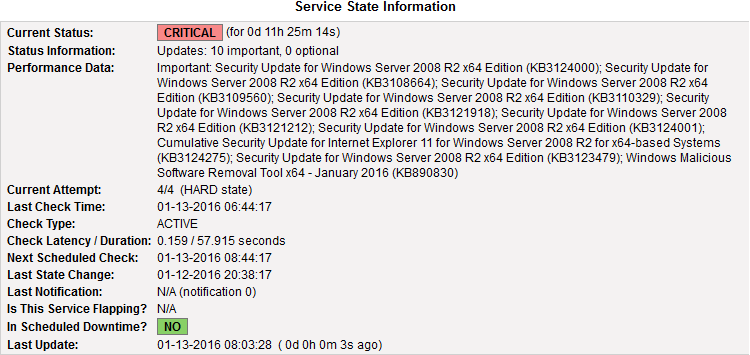
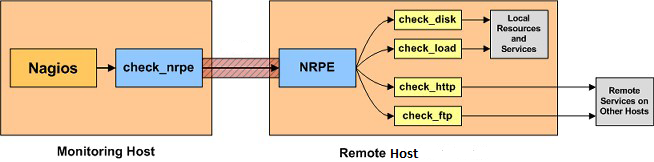
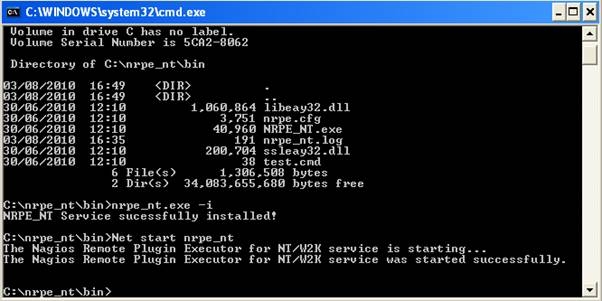
Tenere sotto controllo l’uptime dei nostri server è molto importante, soprattutto se si ha a che fare con macchine in produzione. Per ciò che concerne i sistemi operativi di casa Microsoft (sia client che server), esiste un comando che può tornarci molto utile allo scopo, ovvero:
net stats srv
il quale, basandosi sul servizio Server di Windows, colleziona e fornisce tutta una serie di informazioni associate alla nostra macchina, tra cui, per l’appunto, il suo tempo di attività:
Statistics since 7/11/2016 9:21:08 AM
 Affinchè il suddetto task possa essere effettuato in automatico dal nostro NMS (Nagios), è necessario utilizzare uno scrip (get_uptime.ps1, creato da me allo scopo) da integrare al servizio NRPE_NT. Per ragioni di semplicità e comodità ho deciso di avvalermi di Windows PowerShell per la stesura dello stesso, il cui contenuto è il seguente:
Affinchè il suddetto task possa essere effettuato in automatico dal nostro NMS (Nagios), è necessario utilizzare uno scrip (get_uptime.ps1, creato da me allo scopo) da integrare al servizio NRPE_NT. Per ragioni di semplicità e comodità ho deciso di avvalermi di Windows PowerShell per la stesura dello stesso, il cui contenuto è il seguente:
$critical = $Args[0]
$warning = $Args[1]
if ($warning -and $critical) #both variable are defined and not empty
{
if ($critical -lt $warning)
{
$os = Get-WmiObject win32_operatingsystem
$uptime = (Get-Date) - ($os.ConvertToDateTime($os.lastbootuptime))
$minutes_to_seconds = $Uptime.Minutes*60
$hours_to_seconds = $Uptime.Hours*3600
$days_to_seconds = $Uptime.Days*86400
$uptime_in_seconds = $minutes_to_seconds + $hours_to_seconds + $days_to_seconds
if ($uptime_in_seconds -gt $critical -and $uptime_in_seconds -gt $warning)
{
$Display = "OK: System Uptime is " + $Uptime.Days + " days, " + $Uptime.Hours + " hours, " + $Uptime.Minutes + " minutes"
Write-Output $Display
exit 0
}
elseif ($uptime_in_seconds -gt $critical -and $uptime_in_seconds -le $warning)
{
$Display = "WARNING: System Uptime is " + $Uptime.Days + " days, " + $Uptime.Hours + " hours, " + $Uptime.Minutes + " minutes"
Write-Output $Display
exit 1
}
else
{
$Display = "CRITICAL: System Uptime is " + $Uptime.Days + " days, " + $Uptime.Hours + " hours, " + $Uptime.Minutes + " minutes"
Write-Output $Display
exit 2
}
}
else
{
$Usage = "Usage: .\get_uptime.ps1 <critical threshold in seconds> <warning threshold in seconds>"
$Error1 = "Warning threshold must be greater then the critical one"
Write-Output $Usage
Write-Output $Error1
exit 3
}
}
else
{
$Usage = "Usage: .\get_uptime.ps1 <critical threshold in seconds> <warning threshold in seconds>"
$Error2 = "Warning threshold and critical threshold must be defined"
Write-Output $Usage
Write-Output $Error2
exit 3
}
In soldoni, il suddetto scrip riceve due argomenti da linea di comando, ovvero la soglia critica e quella di warning, espresse entrambe in secondi. Ovviamente, trattandosi di tempo di attività, la prima deve essere strettamente minore della seconda.
Configurazione di NRPE_NT
Salviamo tale scrip all’interno della directory C:\nrpe\Plugins\V2 e successivamente editiamo il file C:\nrpe\Plugins\V2\V2_nrpe_commands.cfg, aggiungendo la seguente direttiva:
# ================================= # Windows System Uptime checks # ================================= command[get_system_uptime]=cmd.exe /c echo C:\nrpe\Plugins\V2\get_uptime.ps1 "$ARG1$" "$ARG2$" | powershell.exe -ExecutionPolicy Bypass -NoLogo -NonInteractive -NoProfile -command -
In particolare, stiamo definendo il comando get_system_uptime che si avvarrà di get_uptime.ps1 per l’individuazione del tempo di attività.
Occorre precisare che l’esecuzione dello scrip non può avvenire richiamando direttamente l’eseguibile powershell.exe, ma deve prima passare per cmd.exe (il cui output, mediante pipe, viene dato in pasto a PowerShell grazie alla direttiva -command –, dove il – finale rappresenta “tutto ciò che proviene dal pipe”). Inoltre, si rende indispensabile bypassare l’executionpolicy di PowerShell, consentendo ad NRPE_NT di lanciare get_uptime.ps1 senza restrizioni.
Infine, riavviamo NRPE_NT per rendere effettive le suddette modifiche:
C:\Users\Administrator> net stop nrpe_nt C:\Users\Administrator> net start nrpe_nt
Configurazione di Nagios
Per prima cosa è necessario creare un apposito comando all’interno del file /etc/nagios/object/commands.cfg:
# nagios-Windows-uptime check command definition
define command {
command_name check_Windows_uptime
command_line /usr/lib64/nagios/plugins/check_nrpe -H $HOSTADDRESS$ -t $ARG1$ -c get_system_uptime -a $ARG2$ $ARG3$
}
Successivamente, all’interno del file che rappresenta l’host da monitorare, è necessario aggiungere un servizio specifico che si avvale del suddetto comando:
define service{
use generic-service ; Name of service template to use
host_name Windows-Server
service_descripion query Windows System Uptime for Microsoft Windows Machine
check_command check_Windows_uptime!30!60!900
}
Ricarichiamo la configurazione di Nagios:
[root@linuxbox ~]# service nagios reload
ed abbiamo finito.
Alla prossima.