Premessa
In questo post ho descritto a grandi linee le diverse politiche di backup ed il motivo per il quale esse sono estramemente importanti. Però, per ciò che concerne la tolleranza ai guasti, soprattutto se si parla di memorie di massa, la prima cosa da fare riguarda la scelta del tipo di RAID da implementare.
Bhè, chiunque abbia mai avuto a che fare con dei server sa sicuramente di cosa sto parlando. Per fare una brevissima introduzione, l’acronimo RAID sta per Redundant Array of Indipendent Disks oppure Redundant Array of Inexpensive Disks, poichè tale sistema è stato pensato per avere ridondanza e per ottenere dischi logici di grandi dimensioni a partire da unità di piccole/medie dimensioni (quindi meno costose).
Inoltre, sono previste diverse tipologie di RAID, ciascuna delle quali presenta delle caratteristiche peculiari, da cui è possibile dedurne i vantaggi e soprattutto gli svantaggi.
RAID a livello hardware oppure a livello software?
Sia ben chiaro che per quanto riguarda i primissimi sistemi RAID, ne era possibile l’implementazione solo a livello hardware, utilizzando opportuni controller. Con l’evolversi della tecnologia sono nati anche dei sistemi software in grado di emulare il comportamento dei suddetti controller. Va detto, però, che essi sono meno performanti dal punto di vista prestazionale. Ergo, se dovete scegliere e non avete budget molto ristretti, il mio consiglio è quello di optare sempre per il RAID hardware.
Livelli RAID
La caratteristica peculiare del RAID è la possibilità di salvare i dati su più unita di archiviazione di massa, facendo diminuire i tempi di accesso (I/O). Tale operazione si chiama, in gergo, data striping.
Altra caratteristica fondamentale dei sistemi RAID è la ridondanza e la tolleranza ai guasti (tranne per il RAID 0).
Detto ciò, vediamo nel dettaglio quali sono i tratti somatici di ciascun livello RAID.
RAID 0
Esso non è proprio un livello RAID a tutti gli effetti. Mi spiego: poichè i sistemi RAID sono nati per offire ridondanza e dato che il RAID 0 non offre tale possibilità, parlare di RAID sembra quasi una forzatura.
Infatti, il RAID 0 consente solo ed esclusivamente di creare un’unità logica di dimensione C a partire da N unità di dimensione D (con N maggiore o uguale a 2). La capacità C sarà data (molto banalmente) dalla formula:
C=N*D
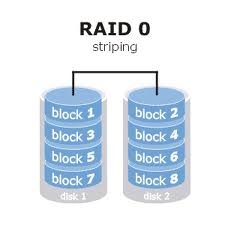
Vantaggi: economico.
Svantaggi: non offre tolleranza ai guasti.
RAID 1
Tale sistema viene anche detto mirroring o shadowing. Esso non fa altro che creare una copia speculare del contenuto di un disco rigido su un altro hard disk. Da ciò si deduce che il numero di dischi da configurare in RAID 1 deve essere pari. Inoltre, la capacità totale sarà pari a quella di un singolo disco (l’altro viene usato solo per la tolleranza ai guasti).
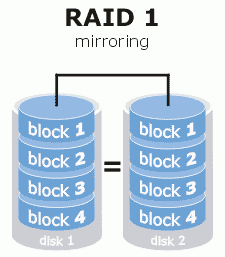
Vantaggi: alta tolleranza ai guasti.
Svantaggi: costo elevato.
RAID 2
Il RAID 2 prevede il data striping a livello di bit. Dunque, da più unità fisiche se ne ricava una logica. Offre, inoltre, una politica di correzione degli errori relativi al singolo bit (grazie al codice di Hamming) e di individuazione (ma non correzione) di errori doppi.
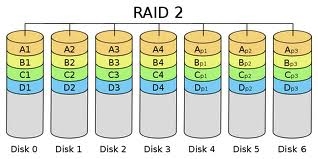
Vataggi: alte performance in sistemi in cui si verificano molti errori durante la fase di I/O.
Svantaggi: performance ridotte in tutti gli altri casi.
RAID 3
Tale sistema (come il RAID 4) è poco utilizzato. Prevede il data striping a livello di byte, dunque tempi di accesso elevati (il byte viene “spalmato” sui dischi, ergo il tempo di accesso per ogni singolo disco va moltiplicato per il numero di unità coinvolte ed in questo modo si ottiene il tempo di accesso reale).
Prevede un meccanismo di tolleranza ai guasti, grazie ad un disco dedicato su cui vengono salvate le informazioni relative al controllo di parità.
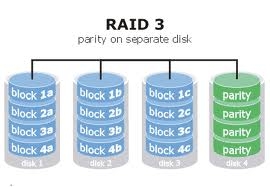
Vantaggi: tolleranza ai guasti.
Svantaggi: tempi di accesso elevati, può sopperire al guasto di un solo disco affinchè i dati possano essere ripristinati. Quindi, se si guastano due dischi contemporaneamente, tutti i dati verranno persi.
RAID 4
Poco utilizzato. Differisce dal RAID 3 solo perchè il data striping avviene a livello di blocco e non di byte. In questo modo vengono risolti i problemi relativi ai lunghi tempi di accesso tipici del RAID 3.
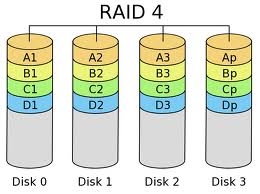
Vantaggi: tempi di accesso ragionevoli, tolleranza ai guasti.
Svantaggi: se si guastano due dischi contemporaneamente i dati verranno persi.
RAID 5
Una vera e propria rivoluzione. Infatti, esso non prevede dei dischi dedicati per il controllo di parità, ma tali informazioni vengono salvate assieme ai dati veri e propri. Purtroppo, però, come già visto per il RAID 3 e per il RAID 4, non è in grado di ripristinare i dati nel caso in cui si guastassero due o più dischi contemporaneamente.
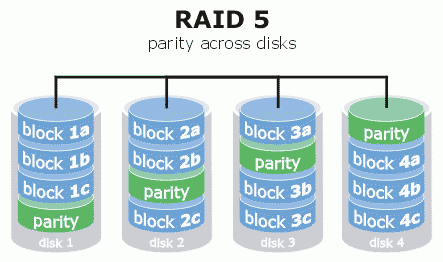
Vantaggi: eliminazione del bottleneck rappresentato dal disco dedicato al controllo di parità.
Svantaggi: operazioni di scrittura lente a causa del calcolo della parità.
RAID 6
Può essere definito “RAID 5 più qualcosa” e quel qualcosa è rappresentato dalla ridondanza del controllo di parità. Infatti, i dati relativi al controllo di parità per uno specifico blocco vengono salvati su due dischi differenti, seguendo direzioni opposte. A titolo di esempio, se l’array è formato dai dischi A B C D e la scrittura avviene sul disco B, il controllo di parità sarà memorizzato su A e su C.
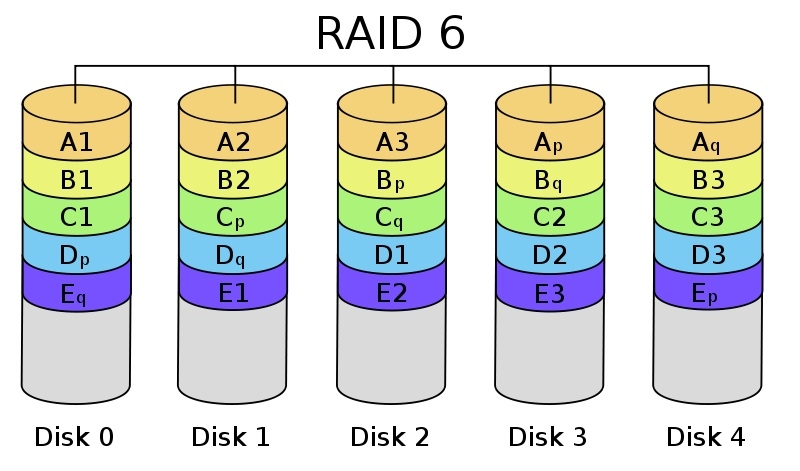
Vantaggi: alta tolleranza ai guasti.
Svantaggi: costoso poichè implica l’uso di un controller ad hoc che lo supporti.
RAID annidati
L’ultima frontiera del RAID è rappresentata dalla possibilità di utilizzare diverse tipologie in modo annidato.
Ad esempio, per ciò che concerne il RAID 0+1 (la seguente figura si legge dal basso verso l’alto), è possibile prevedere il mirroring direttamente sulle unità logiche create attraverso il RAID di tipo 0.
RAID 1
┌——————┴————————┐
RAID 0 RAID 0
┌—————┼—————┐ ┌—————┼—————┐
120GB 120GB 120GB 120GB 120GB 120GB
Due parole sugli spare
Quasi tutti i sistemi RAID che vi ho illustrato (per la precisione tutti tranne il RAID 0) supportano l’hot spare. Questo significa che può essere allocato su uno slot un disco vuoto aggiuntivo, il quale verrà utilizzato automaticamente nel caso in cui una delle memorie di massa che costituiscono l’array si guasti. La differenza tra l’hot spare ed il cold spare sta semplicemente nel fatto che, nell’ultimo caso, il povero sistemista di turno dovrà sostituire il disco guasto con uno vuoto (spegnendo il sistema durante la fase di manutenzione).
Il post termina qui.
Bye.