Prima di approfondire un argomento che avevo già trattato tempo addietro, ovvero il DNS cache poisoning (vedi qui per ulteriori dettagli), è utile illustrare la logica di funzionamento su cui si basa il Domain Name System.
Esistono, in soldoni, 2 tipologie di query DNS:
1) ricorsive;
2) iterative.
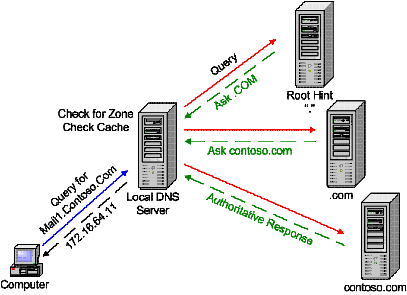
Supponiamo che il client voglia risolvere l’FQDN www.ciao.com
Nel primo caso il client contatterà il proprio resolver (ad esempio il nameserver dell’ISP) sottoponendogli la query. Se la risposta non è contenuta all’interno
della sua cache, esso effettuerà una query ai root nameserver. I root nameserver forniranno una risposta di tipo referral (con ANSWER SECTION vuota ed AUTHORITY SECTION non vuota), contenente una lista di nameserver da contattare per il top level domain (in gergo TLD) .com.
A questo punto il resolver contatterà uno dei nameserver autoritativi appena individuati, il quale fornirà una risposta di tipo referral indicando il nameserver autoritativo per il dominio cercato. Infine, quest’ultimo verrà interrogato e fornirà una risposta alla query (ANSWER SECTION non vuota) indicando l’indirizzo IP relativo al record A (www) ricercato (sempre se il suddetto record esiste).
La risposta, una volta giunta al resolver, verrà quindi girata al client.
 Da notare che sia i root nameserver che i nameserver autoritativi per i TLD forniscono esclusivamente risposte di tipo referral, ergo funzionano solo
Da notare che sia i root nameserver che i nameserver autoritativi per i TLD forniscono esclusivamente risposte di tipo referral, ergo funzionano solo
in modalità iterativa. Infatti, pensate a cosa accadrebbe se ciascun root nameserver interrogato (13 in tutto) iniziasse a fare query ricorsive per individuare
un determinato indirizzo IP… sarebbe una scelta davvero sconveniente (per usare un’espressione moderata) sia in termini di carico che in termini di latenza.
Inoltre, ciascun software che svolge funzioni di namserver utilizza degli algoritmi ben precisi per individuare il server a cui sottoporre la query (root, TLD o autoritativo che sia).
Nella fattispecie, bind usa la tecnica dell’RTT (Round Trip Time), grazie alla quale dovrebbe riuscire ad individuare il namserver più peformante (che coincide con quello che ha risposto più velocemente alla query).
Per ciò che concerne le query iterative, esse prevedono (in generale) il coinvolgimento diretto del client. Per prima cosa esso sottoporrà la query al proprio resolver, che gli risponderà con la lista dei root nameserver (risposta di tipo referral). Il root nameserver successivamente contattato dal client, gli fornirà una risposta di tipo referral indicando una lista di namserver autoritativi per il TLD .com. Dopodichè il client sottoporrà la query ad uno dei predetti nameserver, il quale gli fornirà come risposta una lista dei namserver autoritativi per il dominio ciao.com.
Infine, il client contatterà uno dei nameserver autoritativi per ciao.com che gli girerà la risposta contenente l’indirizzo IP per www.ciao.com (sempre se il record esiste).
Un esempio di query iterativa più essere facilmente ricavato utilizzando dig con l’opzione +trace, ad esempio:
[root@linuxbox ~]# dig +trace www.ciao.com ; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.37.rc1.el6_7.2 <<>> +trace www.ciao.com ;; global options: +cmd . 440639 IN NS b.root-servers.net. . 440639 IN NS m.root-servers.net. . 440639 IN NS h.root-servers.net. . 440639 IN NS k.root-servers.net. . 440639 IN NS a.root-servers.net. . 440639 IN NS i.root-servers.net. . 440639 IN NS f.root-servers.net. . 440639 IN NS e.root-servers.net. . 440639 IN NS j.root-servers.net. . 440639 IN NS d.root-servers.net. . 440639 IN NS l.root-servers.net. . 440639 IN NS g.root-servers.net. . 440639 IN NS c.root-servers.net. ;; Received 496 bytes from 192.168.1.1#53(192.168.1.1) in 38 ms com. 172800 IN NS a.gtld-servers.net. com. 172800 IN NS b.gtld-servers.net. com. 172800 IN NS c.gtld-servers.net. com. 172800 IN NS d.gtld-servers.net. com. 172800 IN NS e.gtld-servers.net. com. 172800 IN NS f.gtld-servers.net. com. 172800 IN NS g.gtld-servers.net. com. 172800 IN NS h.gtld-servers.net. com. 172800 IN NS i.gtld-servers.net. com. 172800 IN NS j.gtld-servers.net. com. 172800 IN NS k.gtld-servers.net. com. 172800 IN NS l.gtld-servers.net. com. 172800 IN NS m.gtld-servers.net. ;; Received 490 bytes from 192.203.230.10#53(192.203.230.10) in 4323 ms ciao.com. 172800 IN NS dns2.progtech.net. ciao.com. 172800 IN NS dns.progtech.net. ;; Received 111 bytes from 192.33.14.30#53(192.33.14.30) in 623 ms www.ciao.com. 86400 IN A 185.60.164.38 ciao.com. 86400 IN NS dns2.progtech.net. ciao.com. 86400 IN NS dns.progtech.net. ;; Received 127 bytes from 80.190.149.57#53(80.190.149.57) in 82 ms
Per completezza, riporto il contenuto di una risposta ad una quey DNS, con le relative sezioni (QUERY, ANSWER, AUTHORITY, ADDITIONAL)
[root@linuxbox ~]# dig libero.it ; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.37.rc1.el6_7.2 <<>> libero.it ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 23298 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 2, ADDITIONAL: 2 ;; QUESTION SECTION: ;libero.it. IN A ;; ANSWER SECTION: libero.it. 300 IN A 37.9.239.32 ;; AUTHORITY SECTION: libero.it. 10799 IN NS n2.libero.it. libero.it. 10799 IN NS n1.libero.it. ;; ADDITIONAL SECTION: n2.libero.it. 10799 IN A 156.154.67.47 n1.libero.it. 10799 IN A 156.154.66.47 ;; Query time: 256 msec ;; SERVER: 10.1.1.1#53(10.1.1.1) ;; WHEN: Tue May 31 09:29:06 2016 ;; MSG SIZE rcvd: 109
essa ci tornerà utile quando vedremo più nel dettaglio la logica su cui si basa il DNS cache poisoning.